BERT
Self-supervised Learning
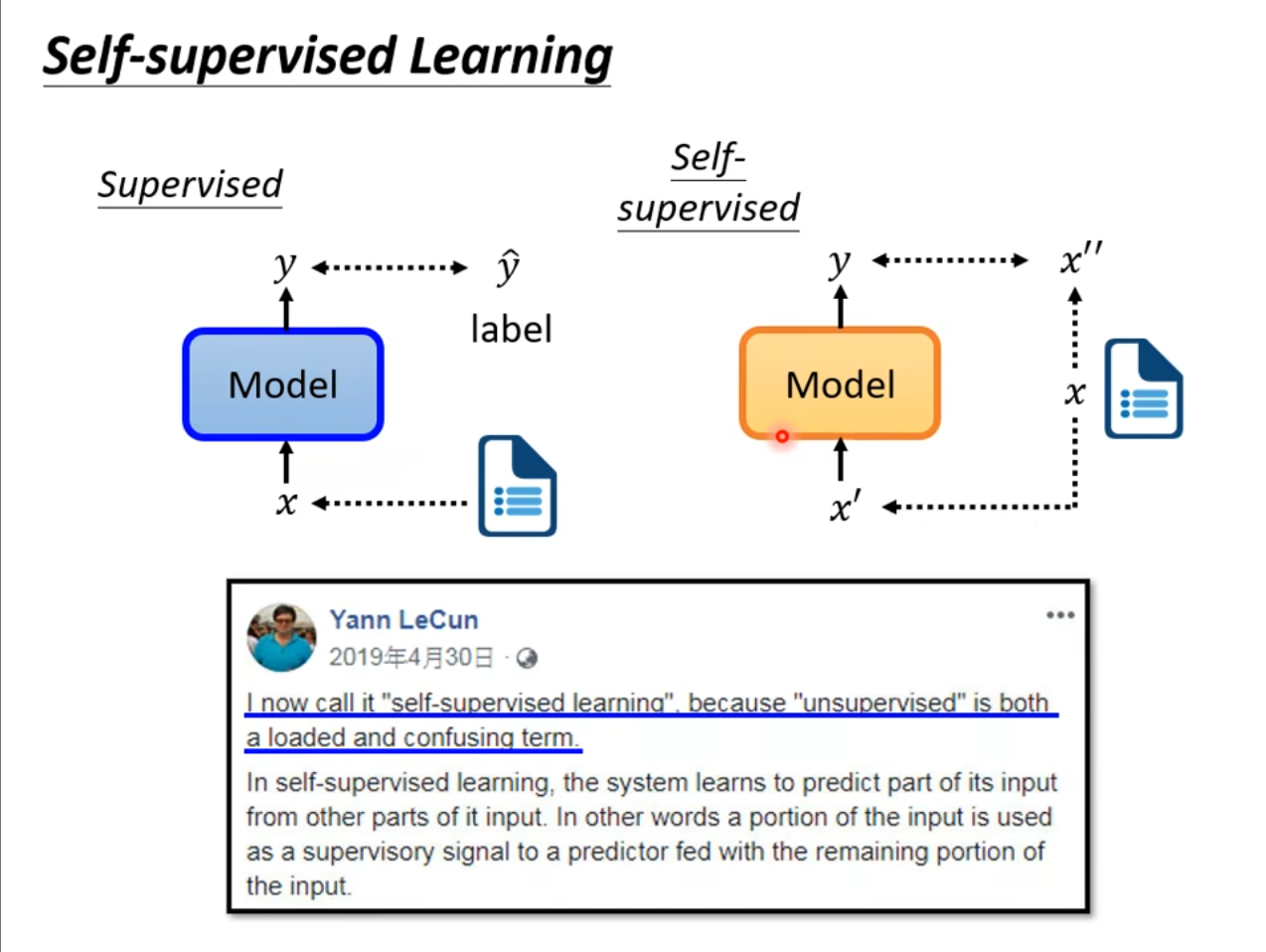
在学习$ BERT $之前我们需要先了解什么是自监督学习,之前我们已经学过了监督学习和非监督学习,但是自监督学习和这两个有所不同,具体来讲就是没有标注好的数据,但是我们将其中的一部分作为标签,另一部分作为输入数据,将输出的数据和标签进行对比,然后使其更加接近。
Masking Input
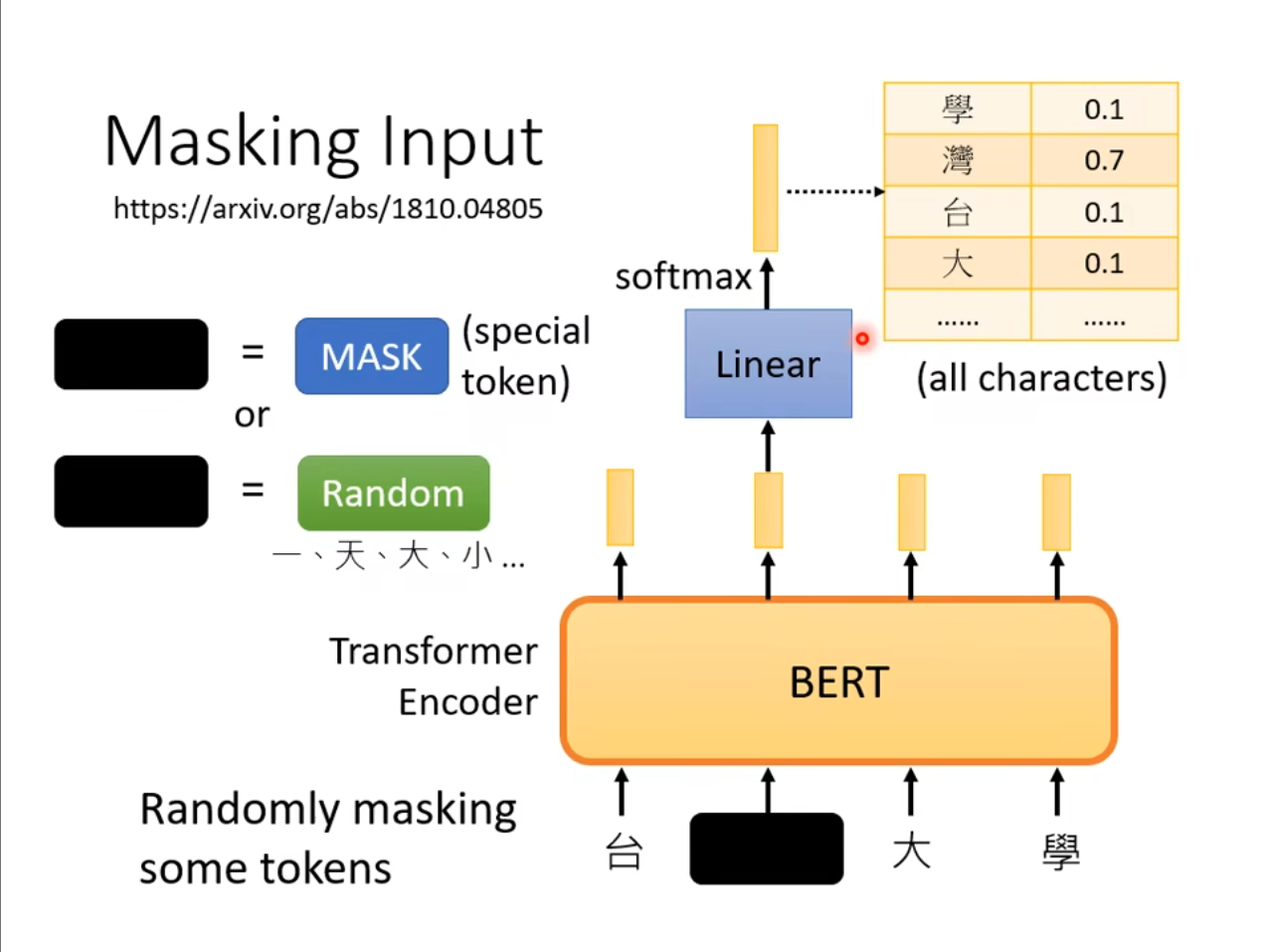
在$ BERT $中,我们是使用了一个$ Transformer $的$ Encoder $,然后通过随机的$ masking $一些$ tokens $可以是使用特殊的符号,也可以是换成随机的符号。由于我们本身是知道原本的数据的,因此我们可以判断输出的数据到底和之前的数据一不一样。
Next Sentence Prediction
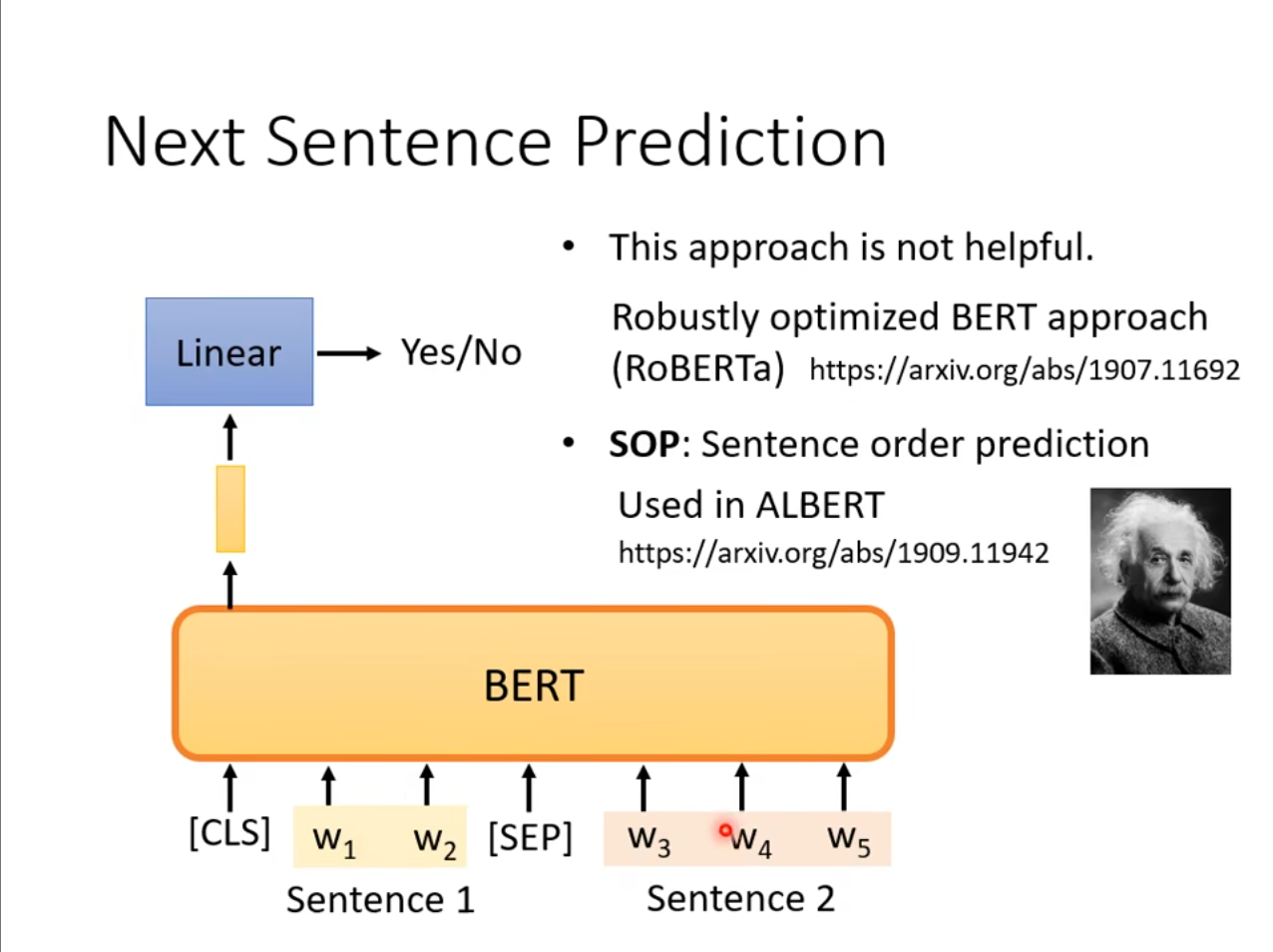
除了屏蔽一些输入的$ tokens $,还用在预测两个句子之间有没有关系,例如选择两个随机的句子,虽然有多个输出,但是仅取$ [CLS] $对应的那个,然后通过这个判断这两个句子之间的关系。
但是从最新的文章来看这种方式似乎用处不大,可能是因为随机的句子本身就关系不大,这个训练对于$ BERT $来讲有些过于简单,因此有人提出了一个新的任务,选择两个本身有关系的句子,但是调换顺序然后再进行判断,这种方式被用在$ ALBERT $这个模型上。
Downstream Tasks
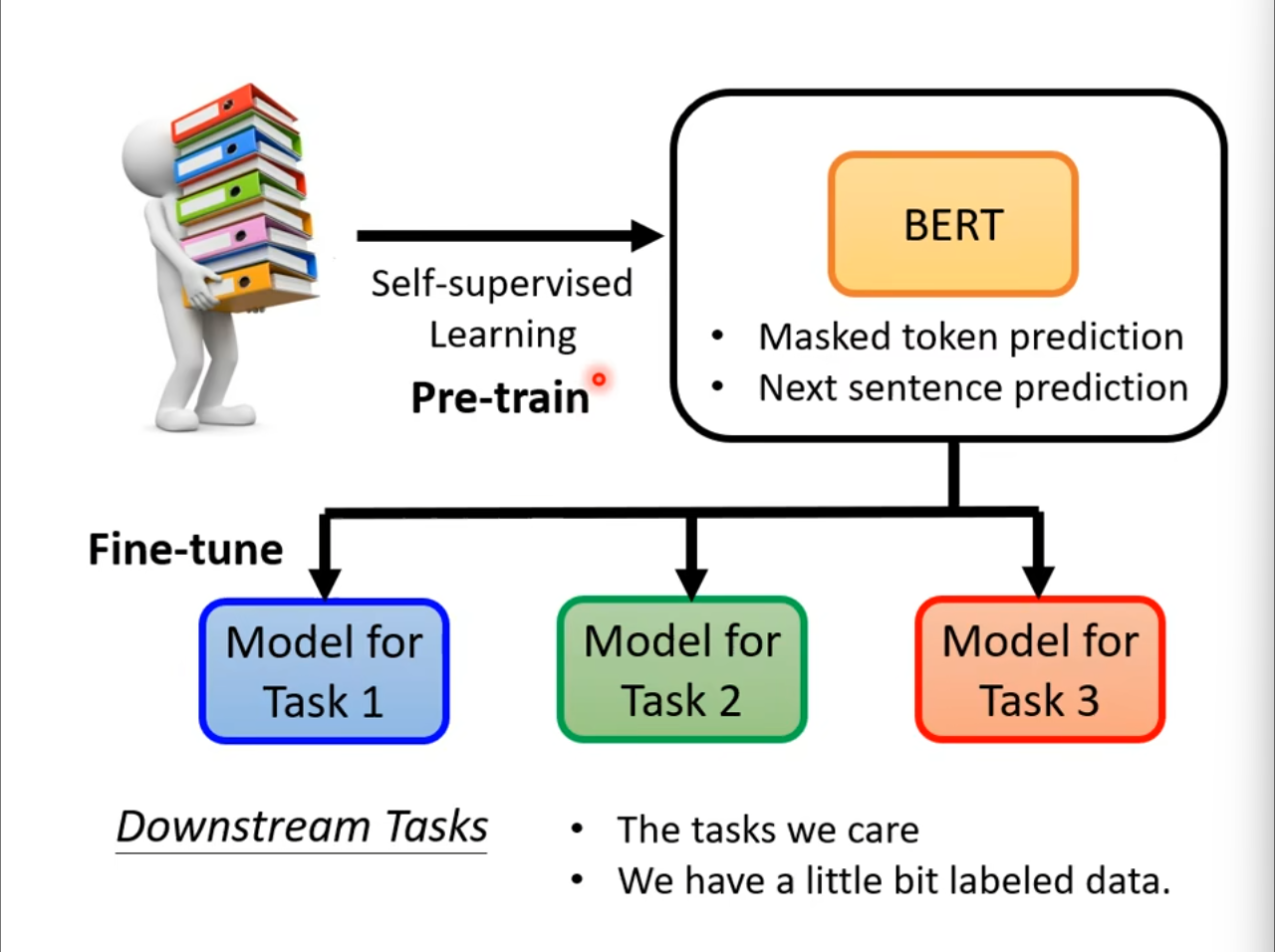
在刚刚的介绍中似乎$ BERT $就仅仅用在预测屏蔽的输入和判断两个句子的关系,但是实际上我们仅需要使用一些有标注的数据进行微调,就可以很好的实现一些下游任务上。

通常我们训练了一个模型之后可以将其应用在这些任务上,然后取平均值判断其效果。
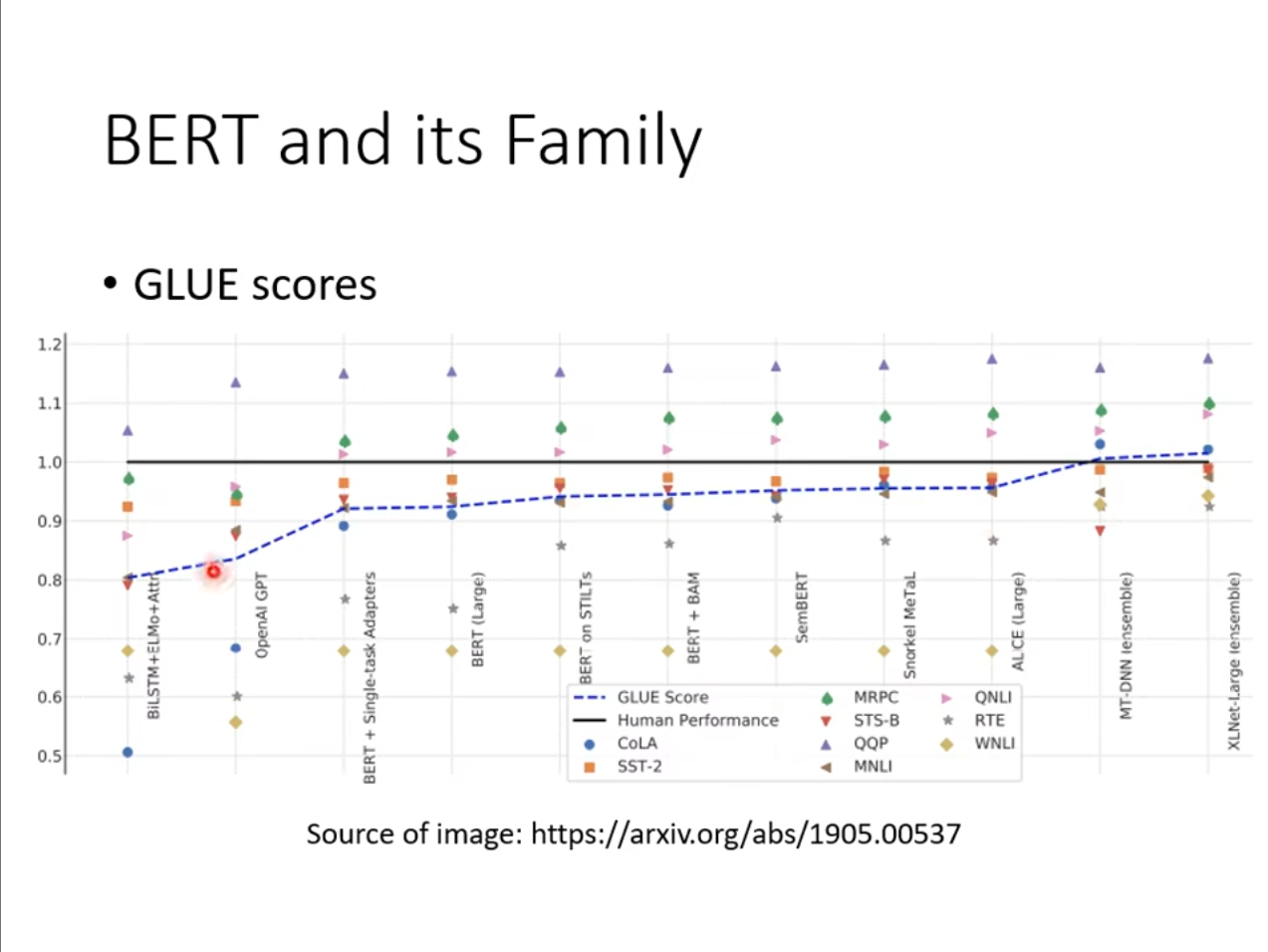
可以看到随着时间的推进,这些任务上机器的表现已经逐渐趋近于人类,甚至高于人类。
How to use
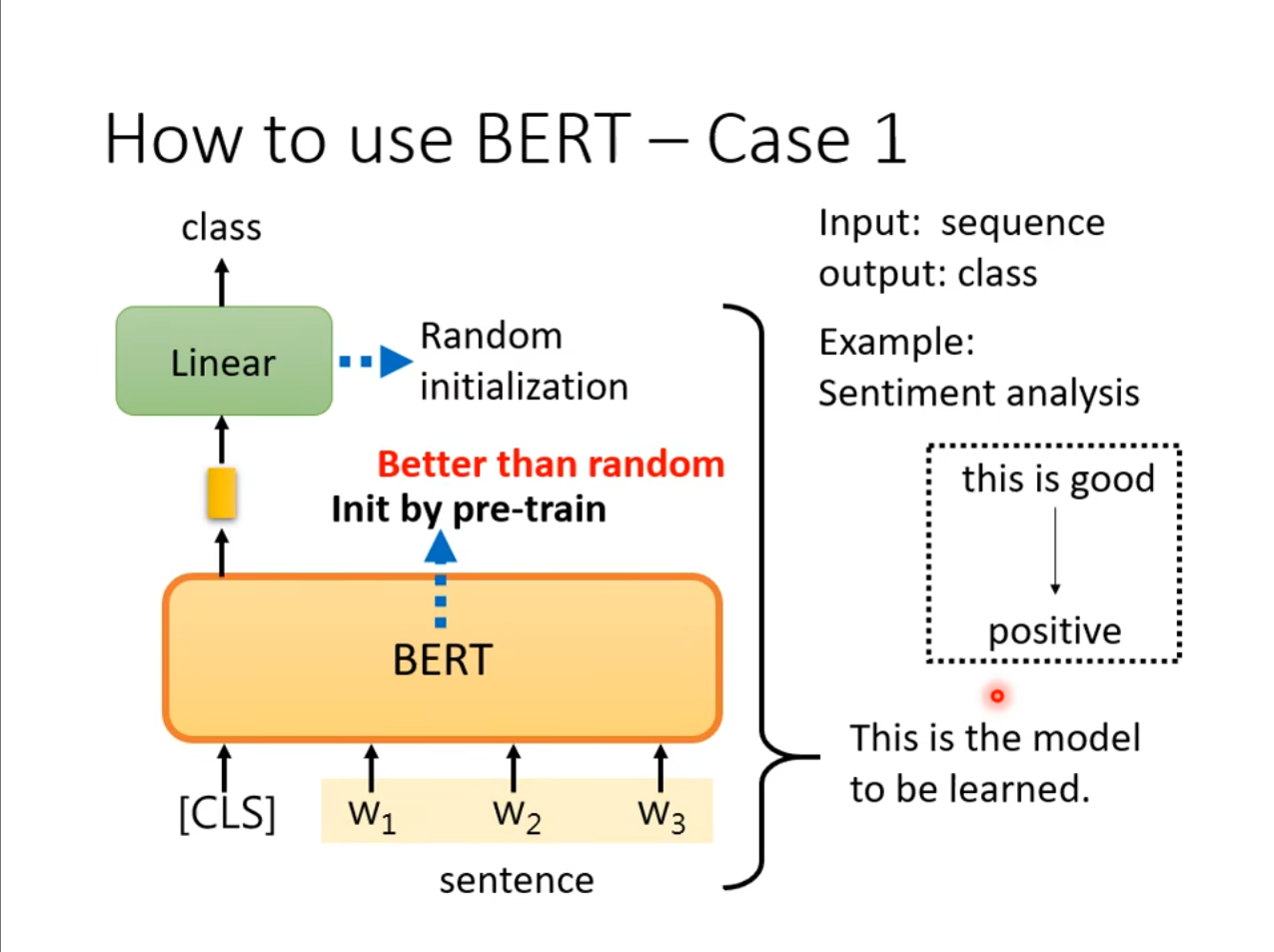 对于怎么使用$ BERT $,使用这么一个简单的例子,输入一个句子,输出一个分类。在这其中我们通过训练好的参数初始化$ BERT $,然后使用随机的初始来初始化我们$ Linear $层,这样的效果是要比全部都随机初始化要好的。
对于怎么使用$ BERT $,使用这么一个简单的例子,输入一个句子,输出一个分类。在这其中我们通过训练好的参数初始化$ BERT $,然后使用随机的初始来初始化我们$ Linear $层,这样的效果是要比全部都随机初始化要好的。
如果具象化的来讲的化,我们可以假设$ BERT $就是一个胚胎干细胞,我们可以将其用于各种各样的任务。
Why does BERT work
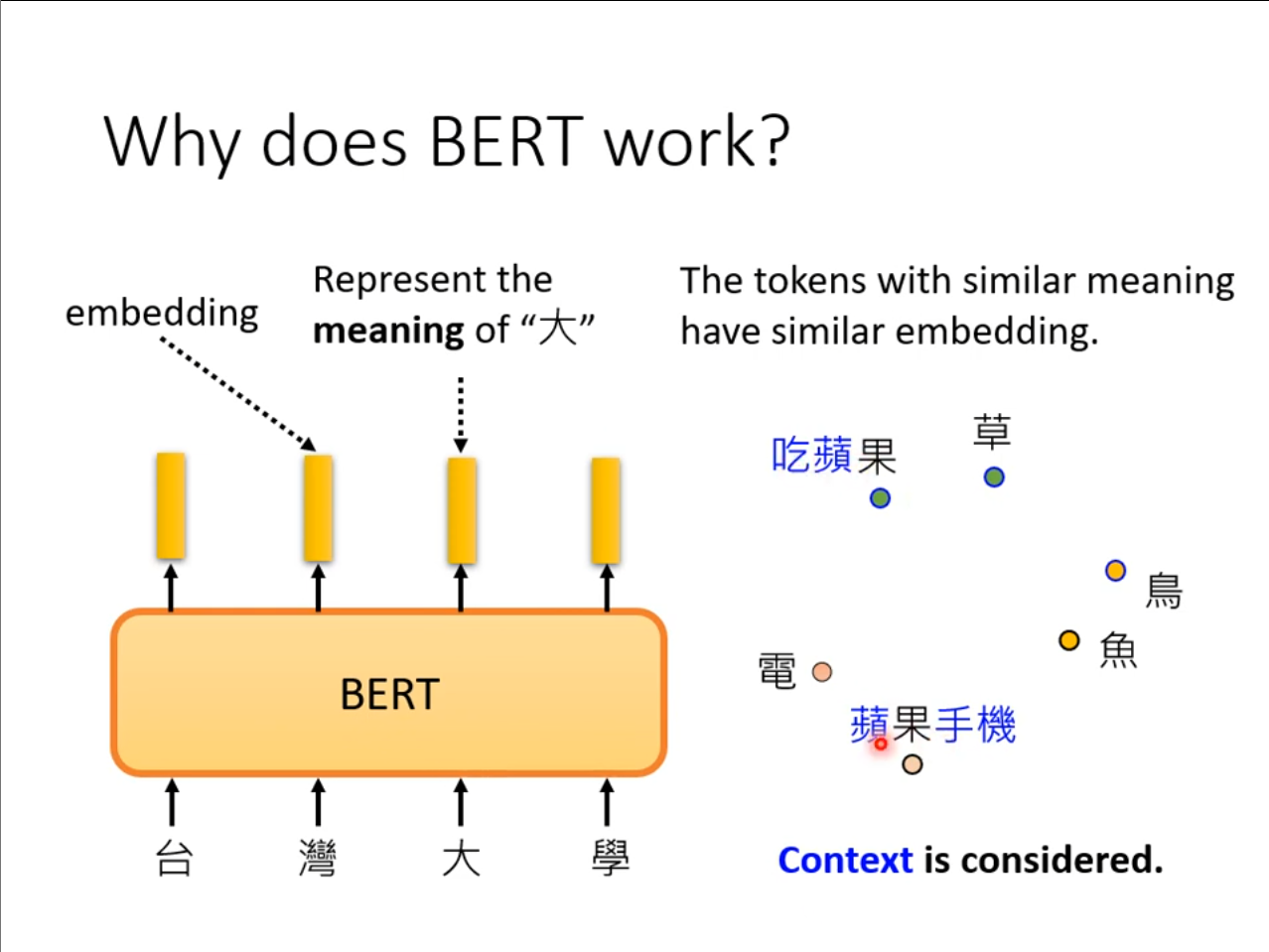
虽然我们应该知道了怎么使用$ BERT $,但是为什么它可以有效依旧是一个很大的问题,其中的一个解释是,我们的输出是一个词的$ embedding $,也就是不同语义下的词分布在不同的位置。
例如,苹果手机中的”果”和吃苹果的”果”一定不是同一个意思,它是从这些词的上下文中学到的,类似的$ tokens $也具有更接近的$ embedding $。不过这也只是一种解释而已,$ BERT $真正的工作原理仍是一个巨大的问题。