Transformer
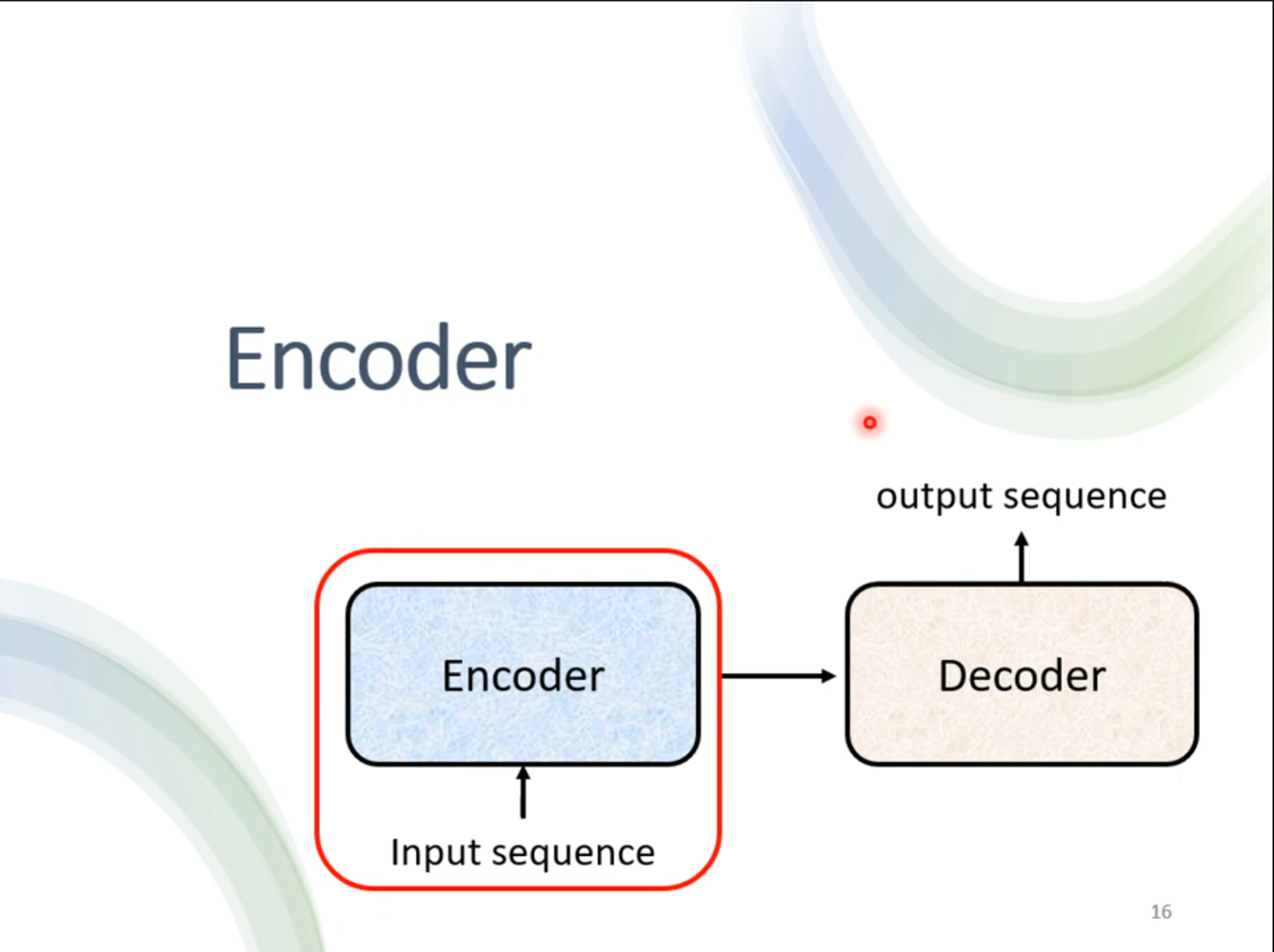
对于$ Transformer $来讲,其中主要分为$ Encoder $和$ Decoder $,接下来首先介绍$ Encoder $。
Encoder
$ Encoder $的主要作用是进行特征提取,这样做是因为原始输入中包含一些无用或干扰信息,这会使模型的性能和泛化性大打折扣。所以在这之前,我们通过$ Encoder $来先对数据进行一次特征提取和挖掘,比如后面会提到$ Encoder $里会有一个自注意力层,正如我们之前文章中提到,自注意力层可以挖掘输入内部元素直接的关系,这是模型直接接受原始输入很难做到。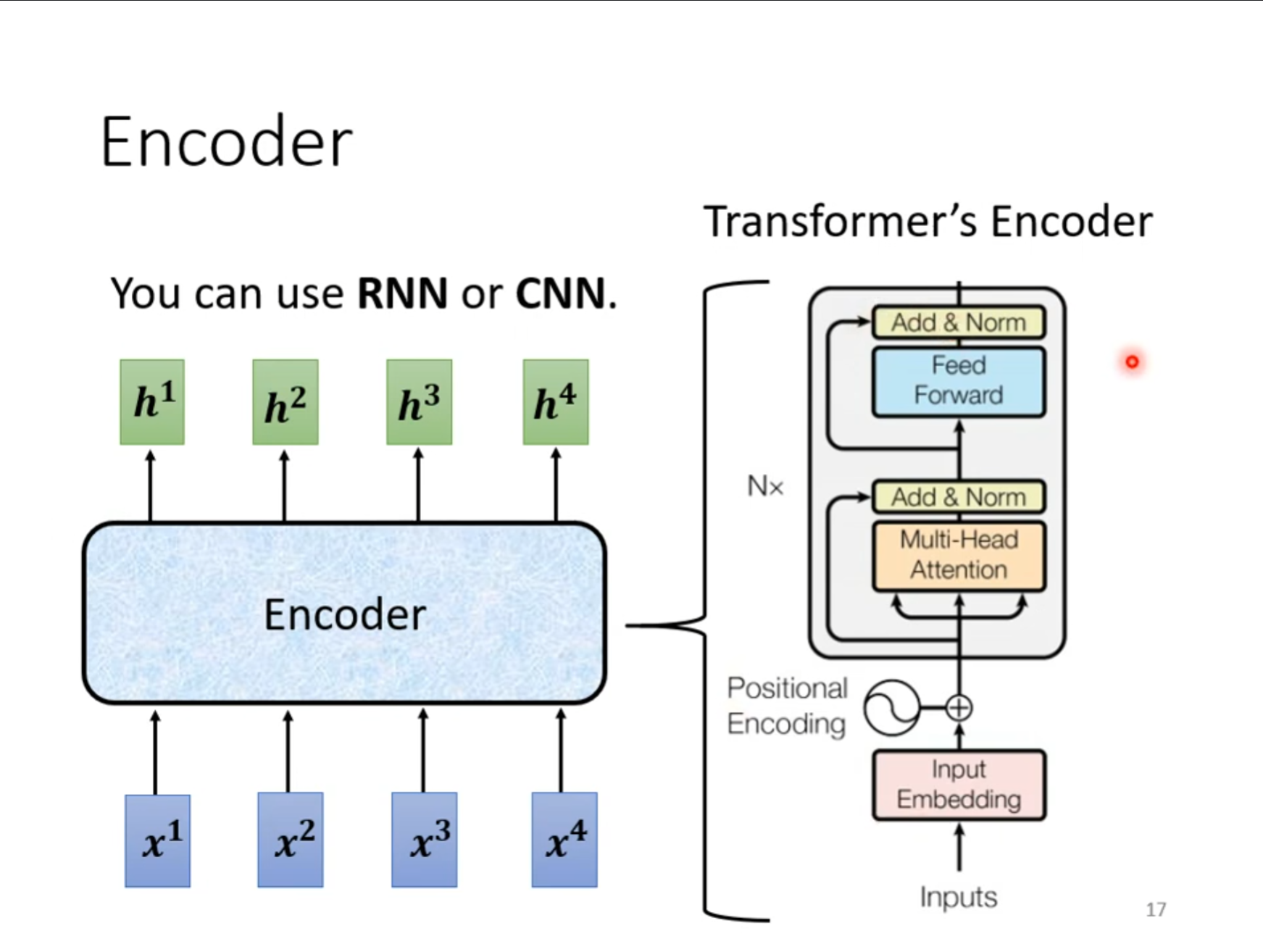
$ Encoder $可以给定一排向量,输出一排同样的向量,对于这个要求$ RNN,CNN $都可以实现,而在$ Transformer $中主要使用的是$ self-attention $,但是这个模型有些复杂,接下来分步介绍这个$ Encoder $。
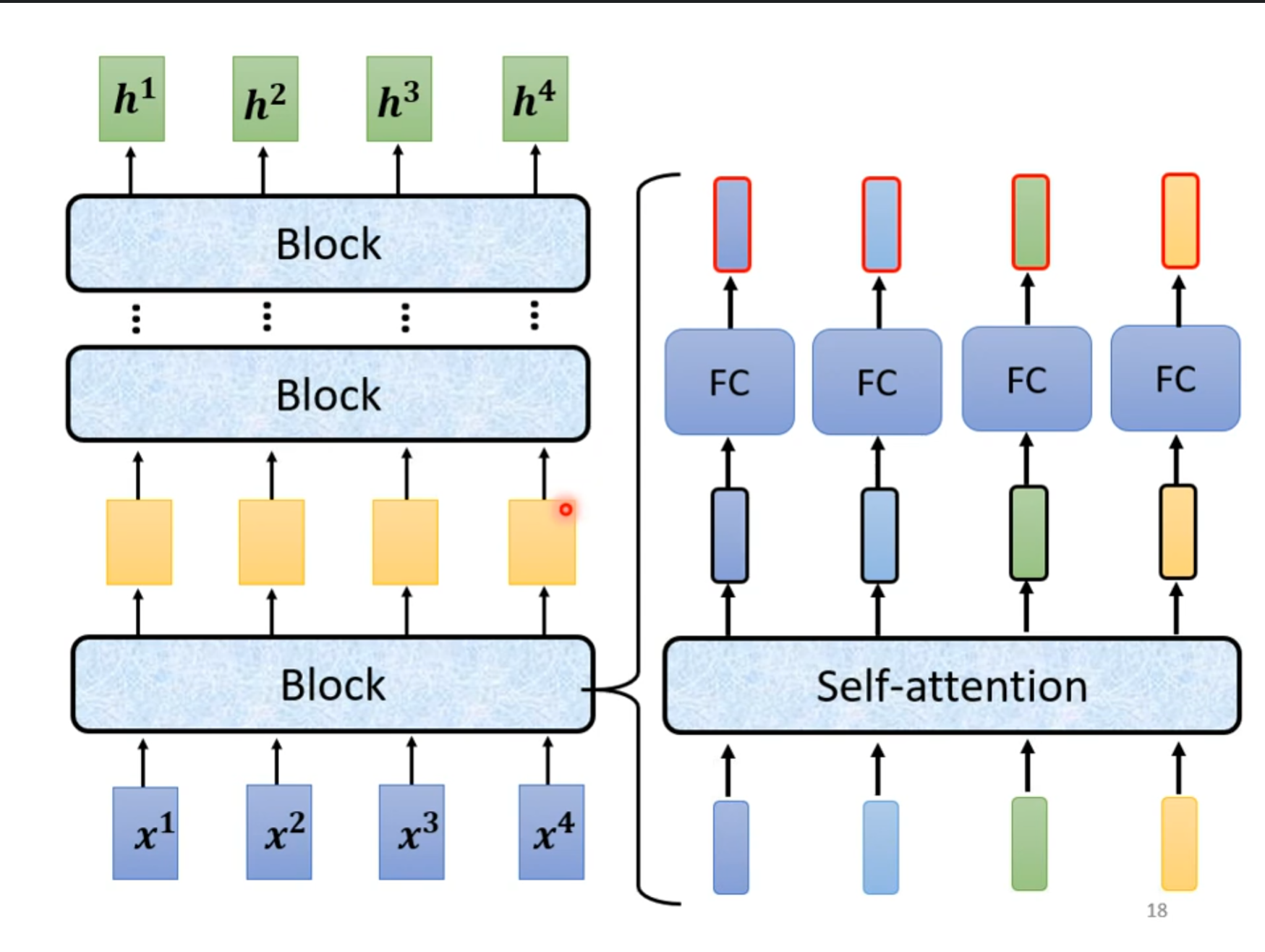
当向量输入之后要经过多个$ Block $,但是每个$ Block $并不是一层网络,而是一个$ self-attention $加上一个$ FC $。
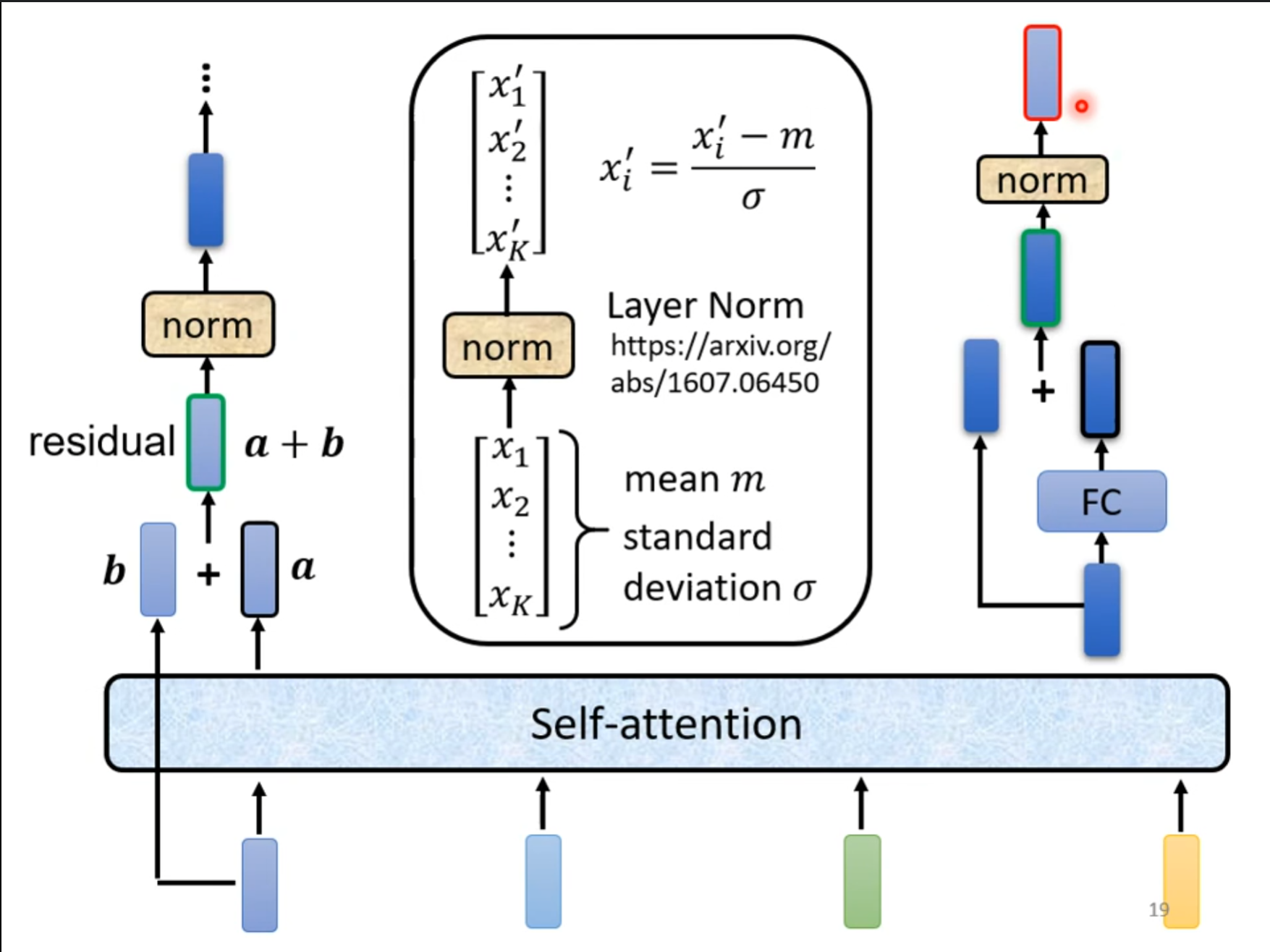
但是这里的$ self-attention $跟之前的有些不同,还需要加上$ residual $和$ norm $,同时在$ FC $也加上这两个操作。需要注意的是这里的是层归一化。
层归一化和批量归一化:
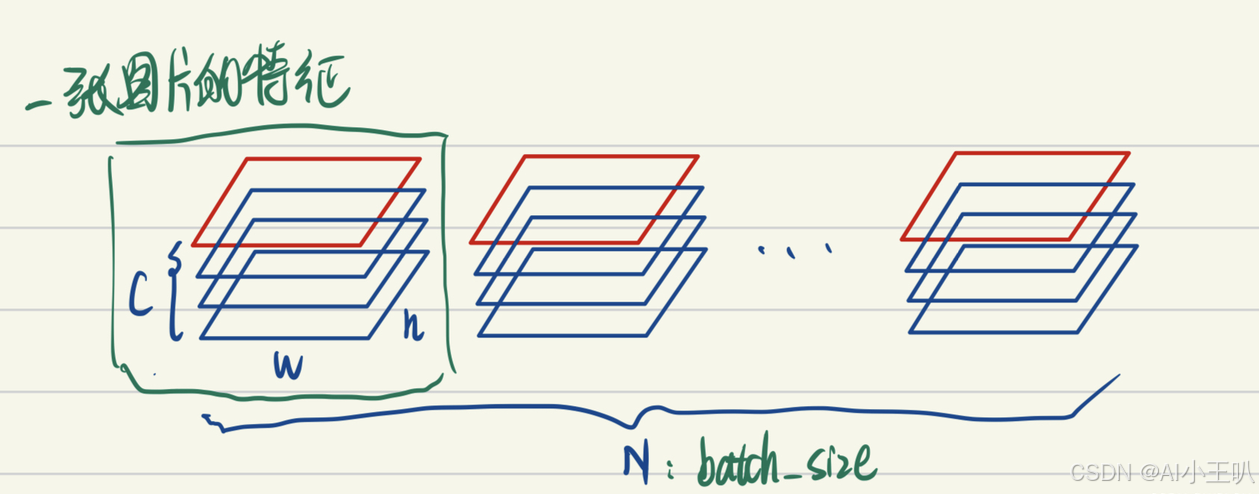
$ BatchNorm $把一个$ batch $中同一通道的所有特征(如下图红色区域)视为一个分布(有几个通道就有几个分布),并将其标准化。这意味着:
- 不同图片的的同一通道的相对关系是保留的,即不同图片的同一通道的特征是可以比较的
- 同一图片的不同通道的特征则是失去了可比性
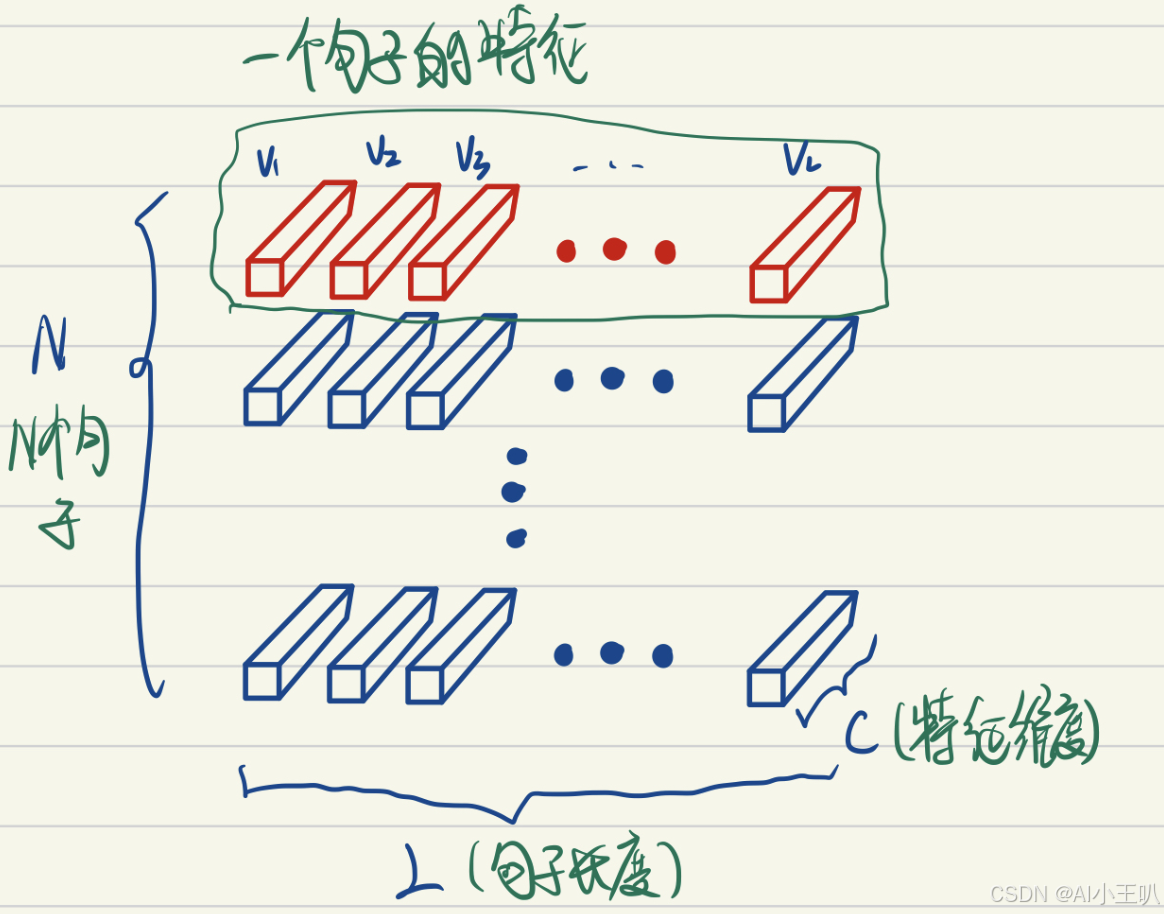
$ LayerNorm $把一个样本的所有词义向量(如下图红色部分)视为一个分布(有几个句子就有几个分布),并将其标准化。这意味着:
同一句子中词义向量(上图中的$ V1, V2, …, VL $)的相对大小是保留的,或者也可以说$ LayerNorm $不改变词义向量的方向,只改变它的模。不同句子的词义向量则是失去了可比性。
用于$ NLP $领域解释:
考虑两个句子,“教练,我想打篮球!” 和 “老板,我要一打包子。”。通过比较两个句子中 “打” 的词义我们可以发现,词义并非客观存在的,而是由上下文的语义决定的。因此进行标准化时不应该破坏同一句子中不同词义向量的可比性,而$ LayerNorm $是满足这一点的,$ BatchNorm $则是不满足这一点的。且不同句子的词义特征也不应具有可比性,$ LayerNorm $也是能够把不同句子间的可比性消除。
$ Transformer $使用$ LayerNorm $而不是$ BatchNorm $的主要原因是$ LayerNorm $更加适合处理变长的序列数据。在$ Transformer $中,由于输入序列的长度是可变的,因此每个序列的批量统计信息(如均值和方差)也是不同的。而$ BatchNorm $是基于整个批量数据来计算统计信息的,这可能导致在处理变长序列时性能下降。相比之下,$ LayerNorm $是在每个样本的维度上进行归一化的,因此不受序列长度变化的影响。
在$ Transformer $中,$ LayerNorm $通常被放置在多头注意力机制和前馈神经网络的输出之后。通过对这些层的输出进行归一化,可以使得后续层的输入保持在一个相对稳定的范围内,有助于模型的训练。
简单对比如下:
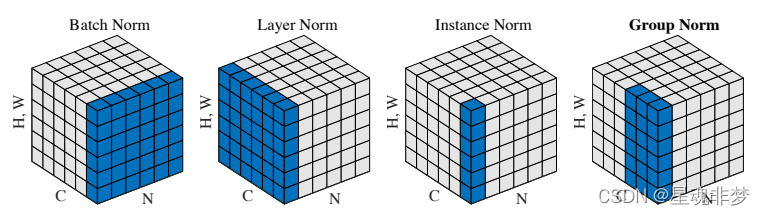
参照于:
【深度学习中的批量归一化BN和层归一化LN】BN层(Batch Normalization)和LN层(Layer Normalization)的区别_bn和ln-CSDN博客
Transformer 系列三:Encoder编码器和Decoder解码器_transformer编码器-CSDN博客
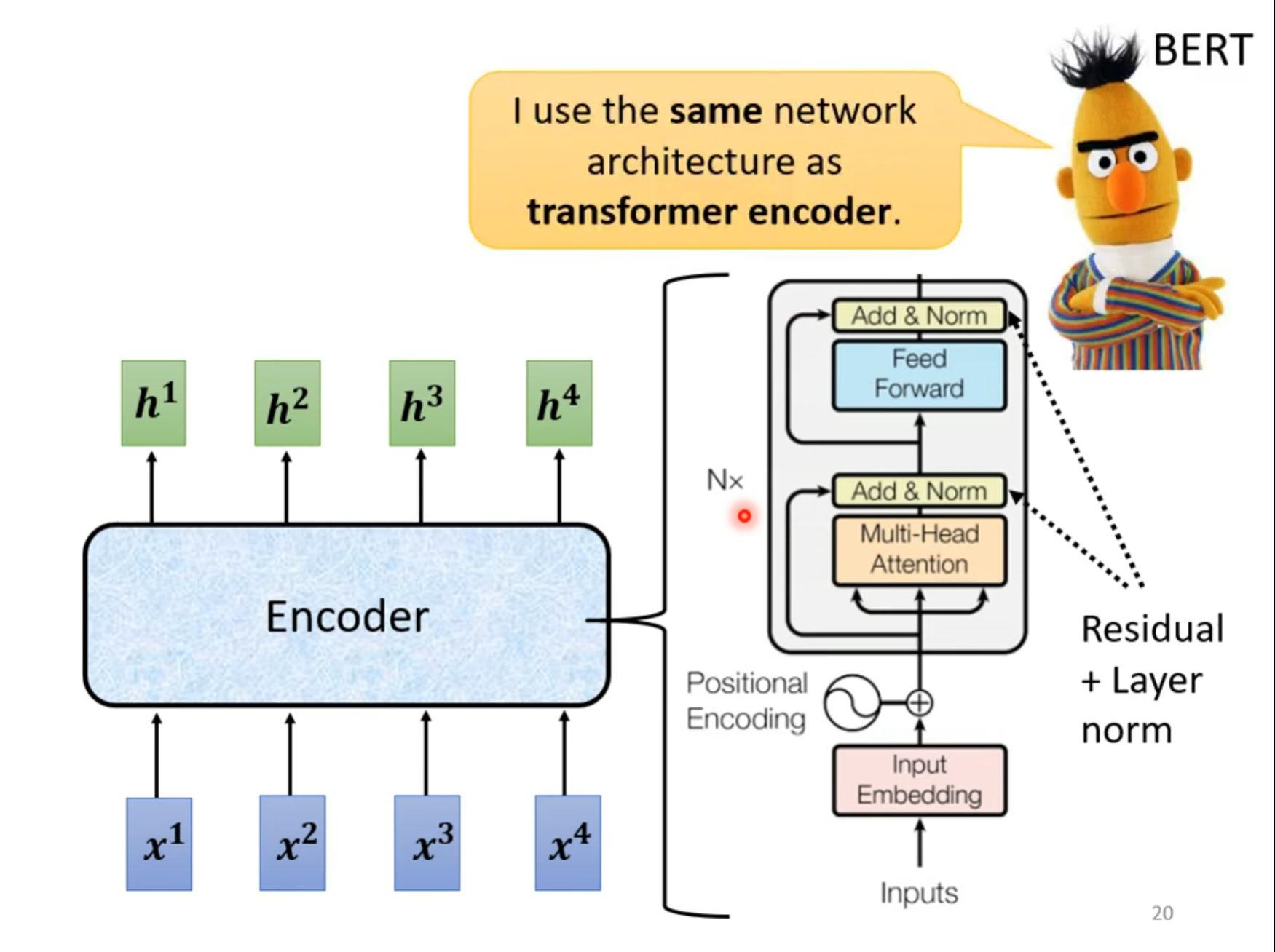
对比一下刚刚看到的模型,只是将$ Self-Attention $换成了$ Mult-Head\ Attention $,同时在输入之前加上了位置编码。
同时将全连接层换成了一个前馈神经网络,其实就是一个简单的两层全连接网络,用于进一步处理多头注意力机制的输出。这个网络首先通过一个线性变换将输入映射到一个更高维的空间中,然后通过一个非线性激活函数(如$ ReLU $)增加网络的非线性能力,最后再通过另一个线性变换将输出映射回原始维度。
在自注意力层后面增加前馈神经网络层的原因:
- 特征提取:$ FFN $通过两层全连接层(通常是线性层),对来自自注意力层的输出进行进一步的特征提取。这有助于模型学习到更深层次的、非线性的特征表示。
- 增加模型容量:通过引入额外的参数和非线性激活函数,$ FFN $增加了模型的容量,使得模型能够捕捉更复杂的数据模式和关系。
- 与自注意力机制互补:自注意力机制擅长捕捉序列内部的长距离依赖关系,而$ FFN $则专注于在给定的表示上进行特征转换。这种组合使得$ Transformer $能够有效地处理各种语言和序列任务。
- 提高泛化能力:$ FFN $通过增加模型的复杂性,有助于提高模型对未见数据的泛化能力。
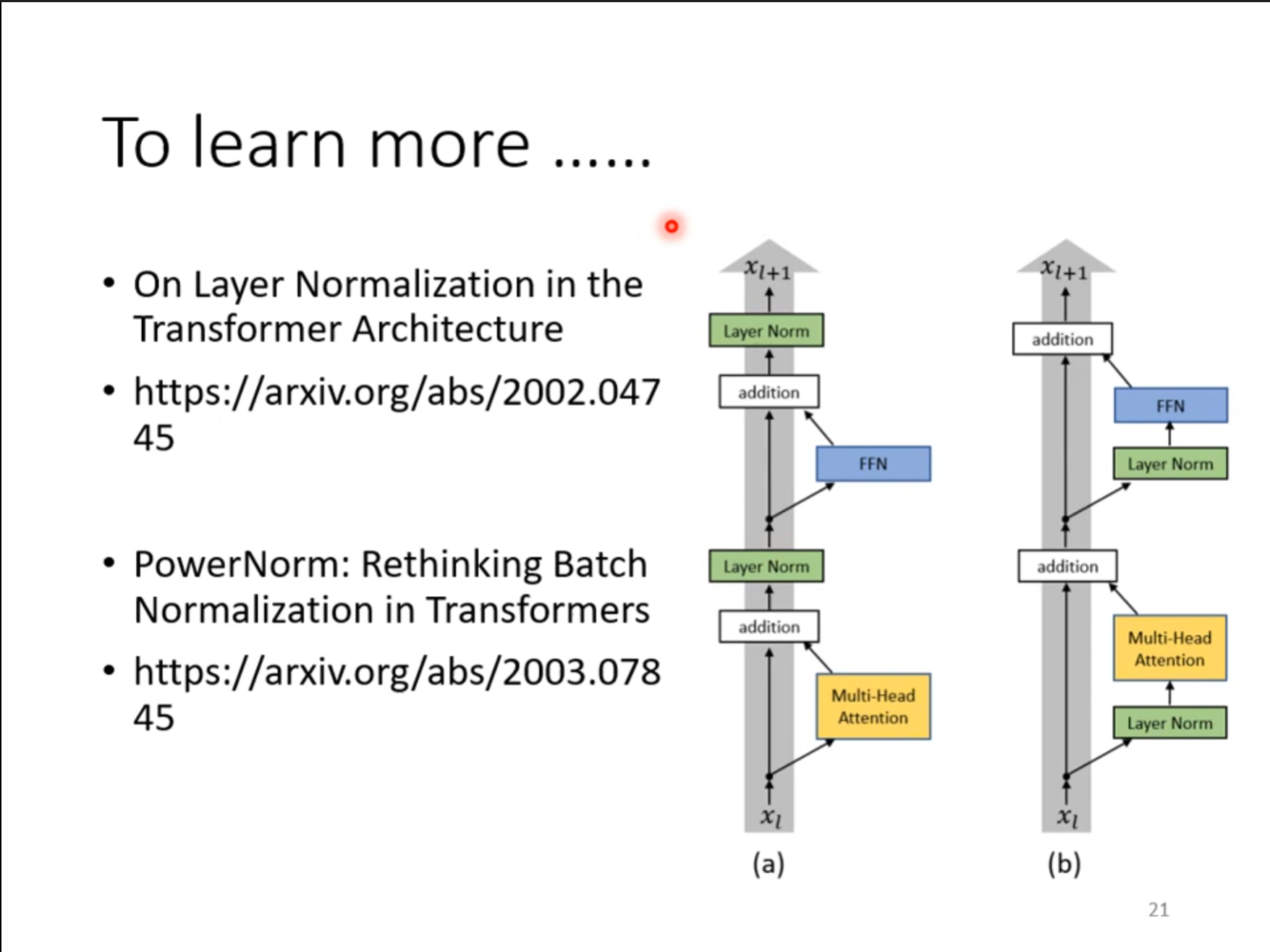
其实$ Encoder $的架构并不是一定要这样设计,我们可以将其中的归一化的操作提前进行,这样的效果似乎看起来更好。
Decoder
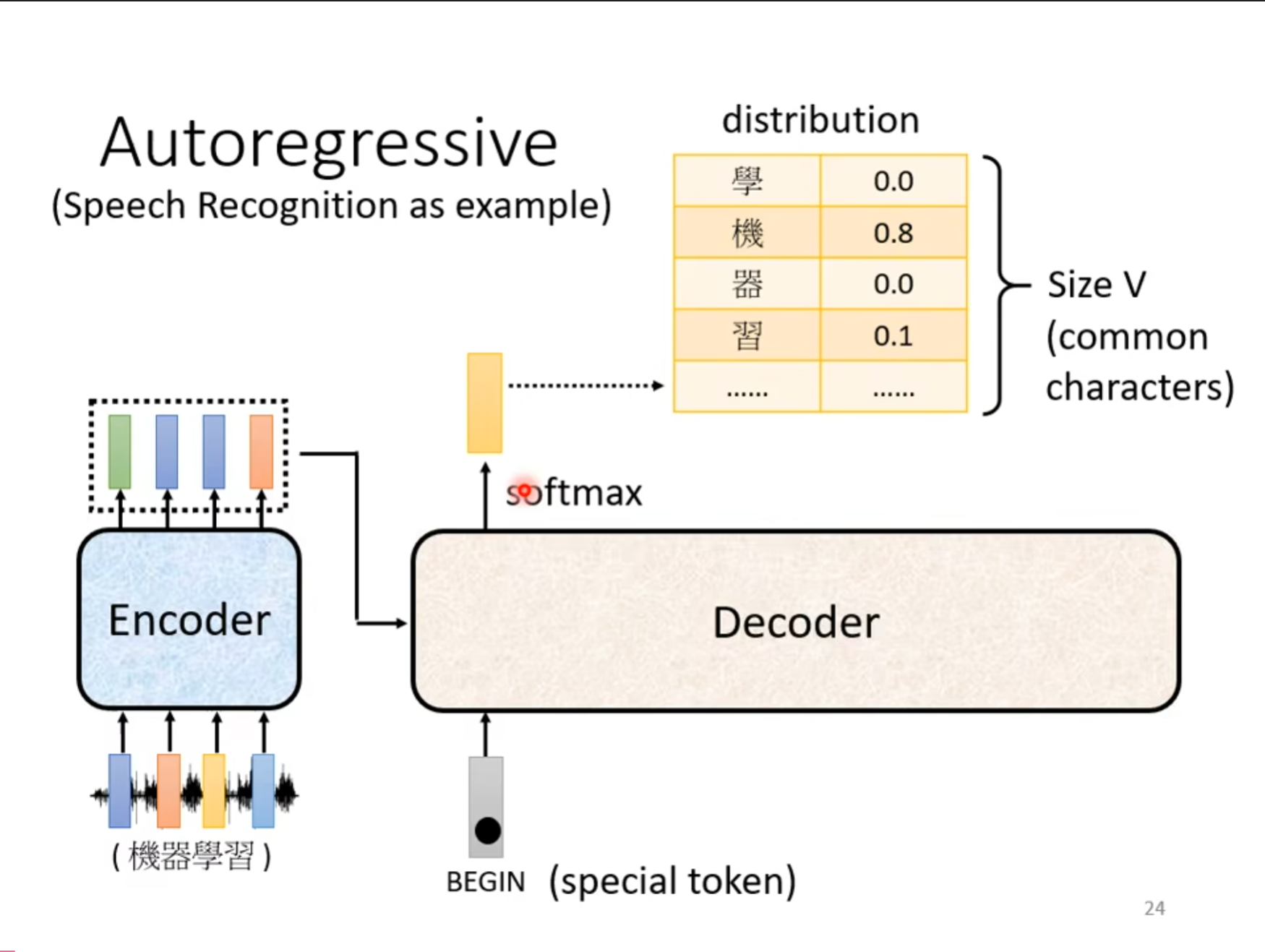
我们刚才介绍了$ Encoder $,现在我们先不考虑$ Encoder $的输出怎么作为$ Decoder $的输入,现在假设已经可以传递。首先使用一个$ BEGIN $作为一个输入,同时根据这个输入得到一个输出,经过一个$ softmax $之后得到一个表,选择其中概率最大的值,将这个作为我们的预测结果,同时这个表的长度就是我们希望的词的范围大小,可能是中文的常用词,大概$ 3000,5000 $字左右,也可能是例如英文的常用词的大小。
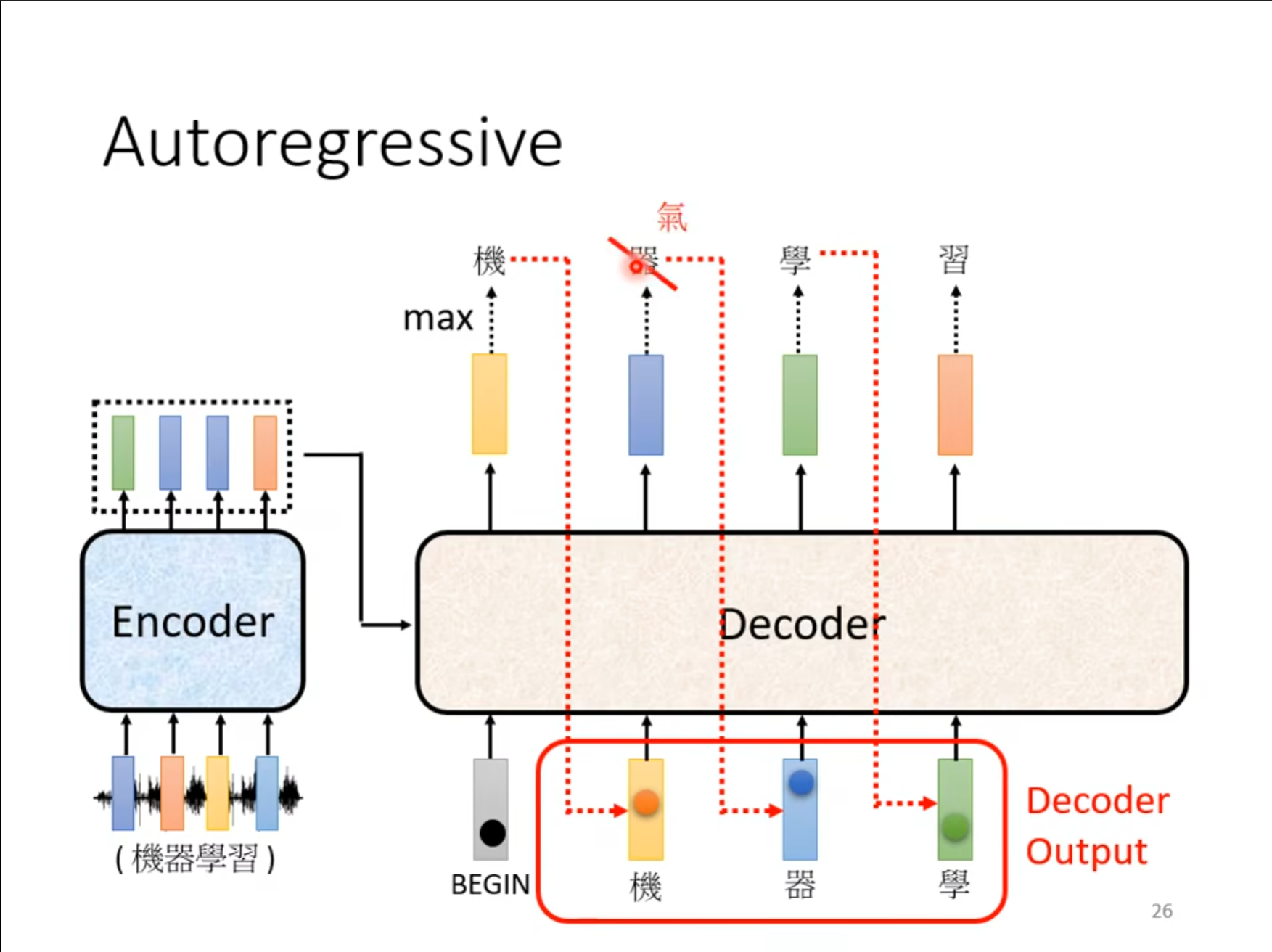 接着使用上次的输出作为这次的输入,对于如果中间出现了错误是否会导致接下来的结果全部错误再下面会提到。
接着使用上次的输出作为这次的输入,对于如果中间出现了错误是否会导致接下来的结果全部错误再下面会提到。
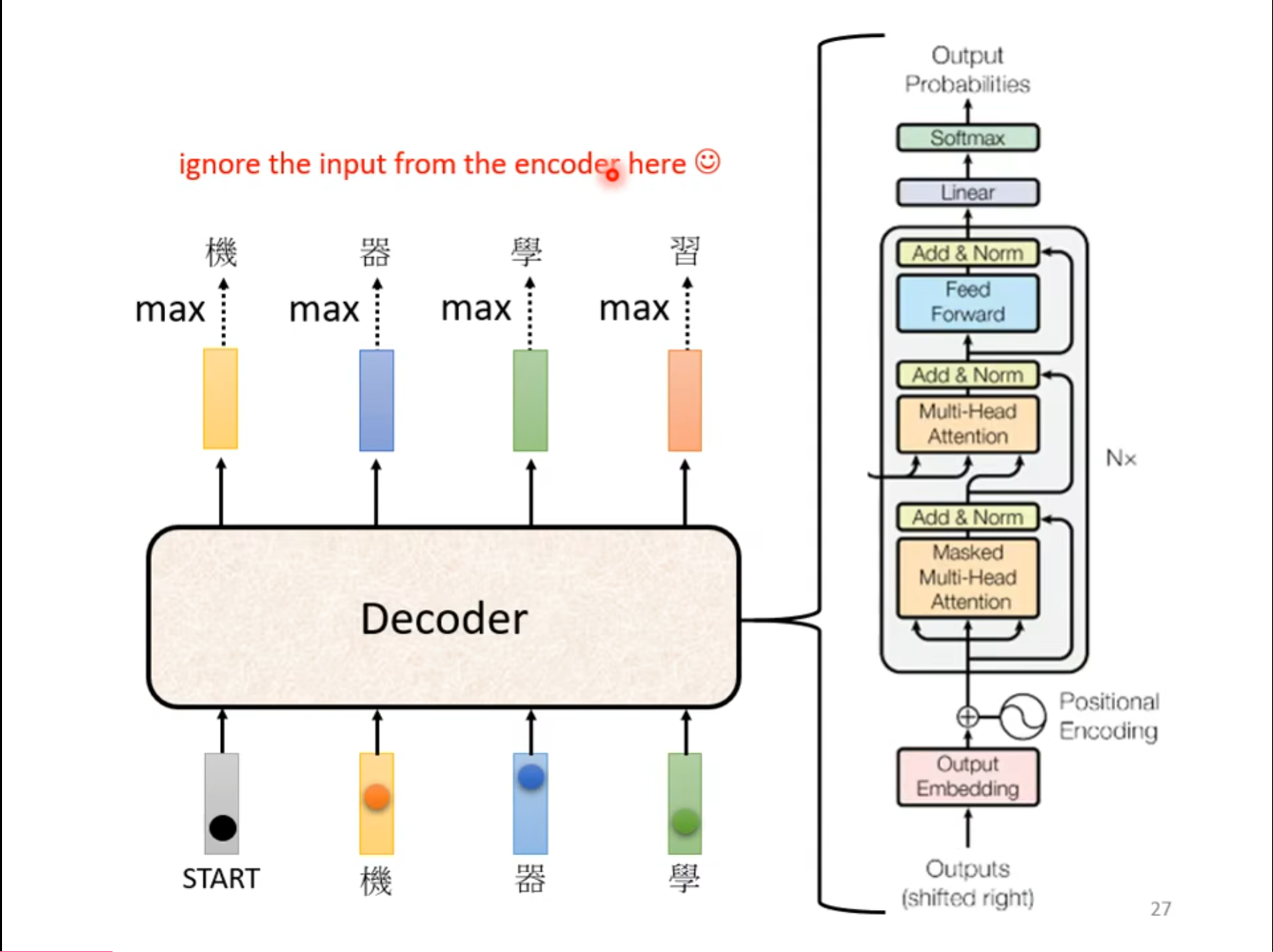
这个是$ Decoder $的结构图,看起来比$ Encoder $还要复杂,但是如果把中间的部分删除,其实别的部分基本一样。
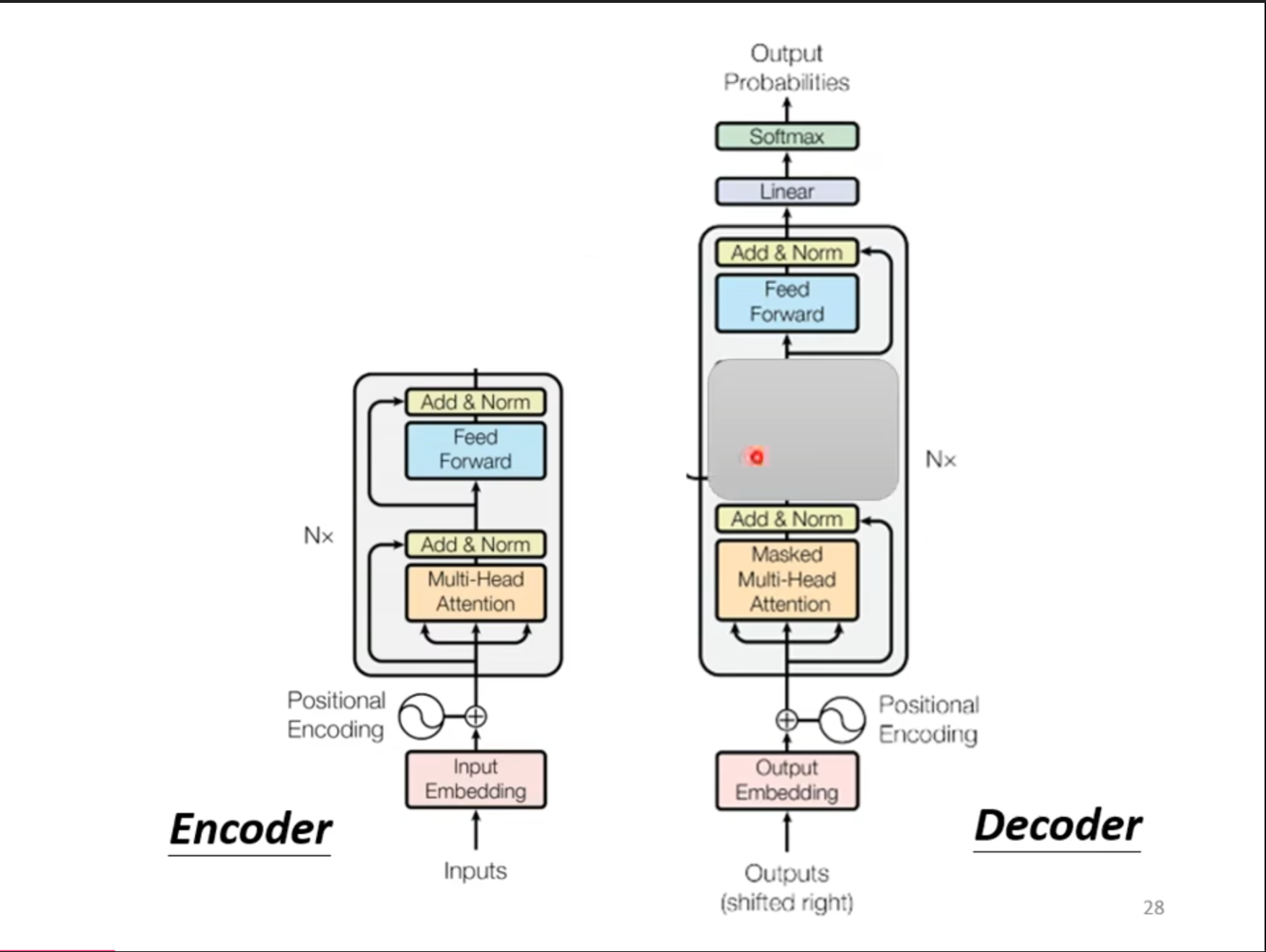
可以看到,其余部分基本上一样,并没有什么很大的差别,只是其中的$ Multi-Head\ Attention $换成了$ Masked \ Multi-Head \ Attention $。
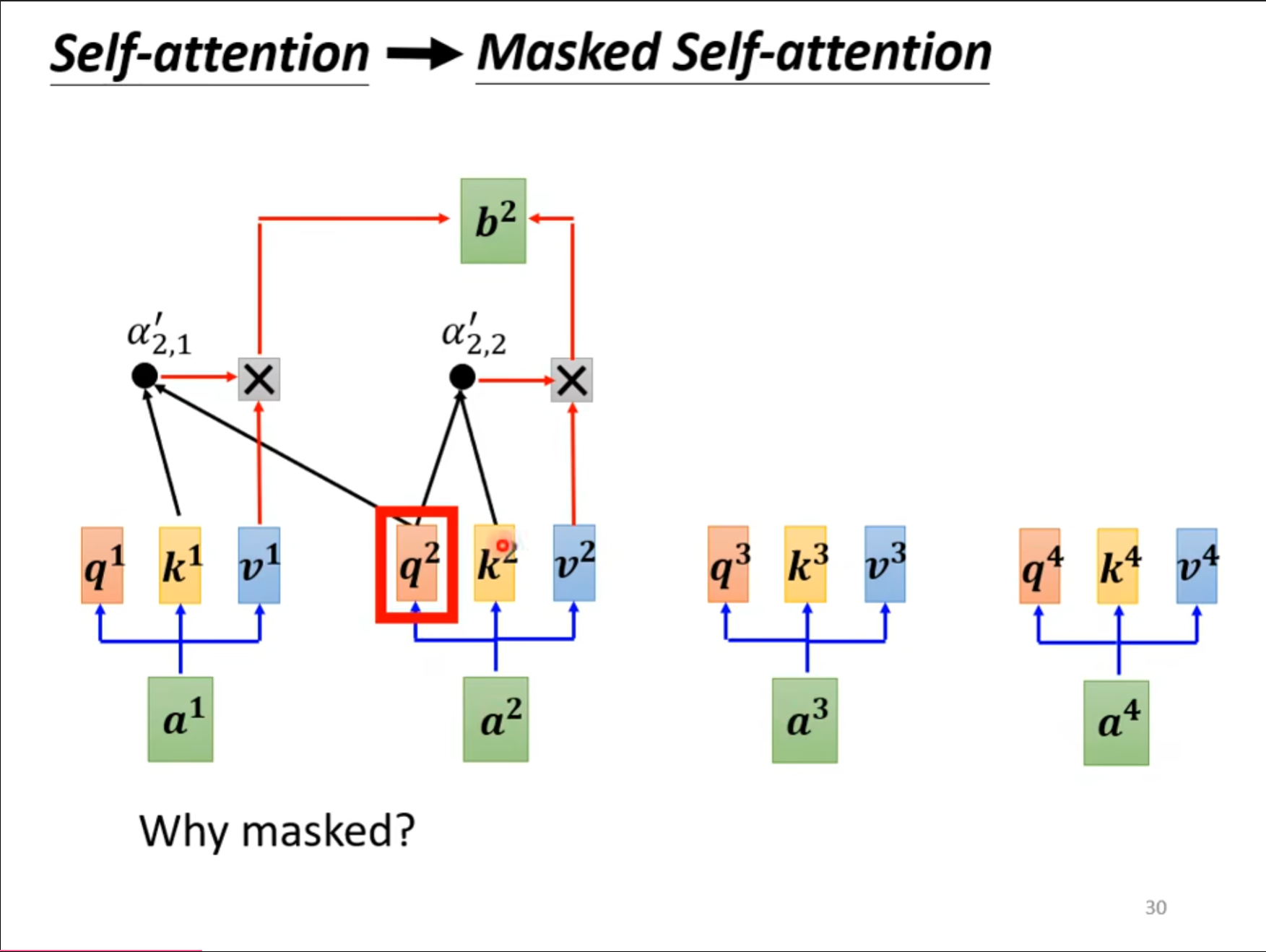
对于$ Masked \ Multi-Head \ Attention $来讲,其中的主要区别就是,当$ q^2 $是,对应的$ k $只有$ k^1,k^2 $,只可以查询到当前和再前面的值,其实从刚才的$ Decoder $的原理也可以理解,其中的$ a^1,a^2,a^3,a^4 $并不是同时出现的,因此需要使用$ Masked $的形式。
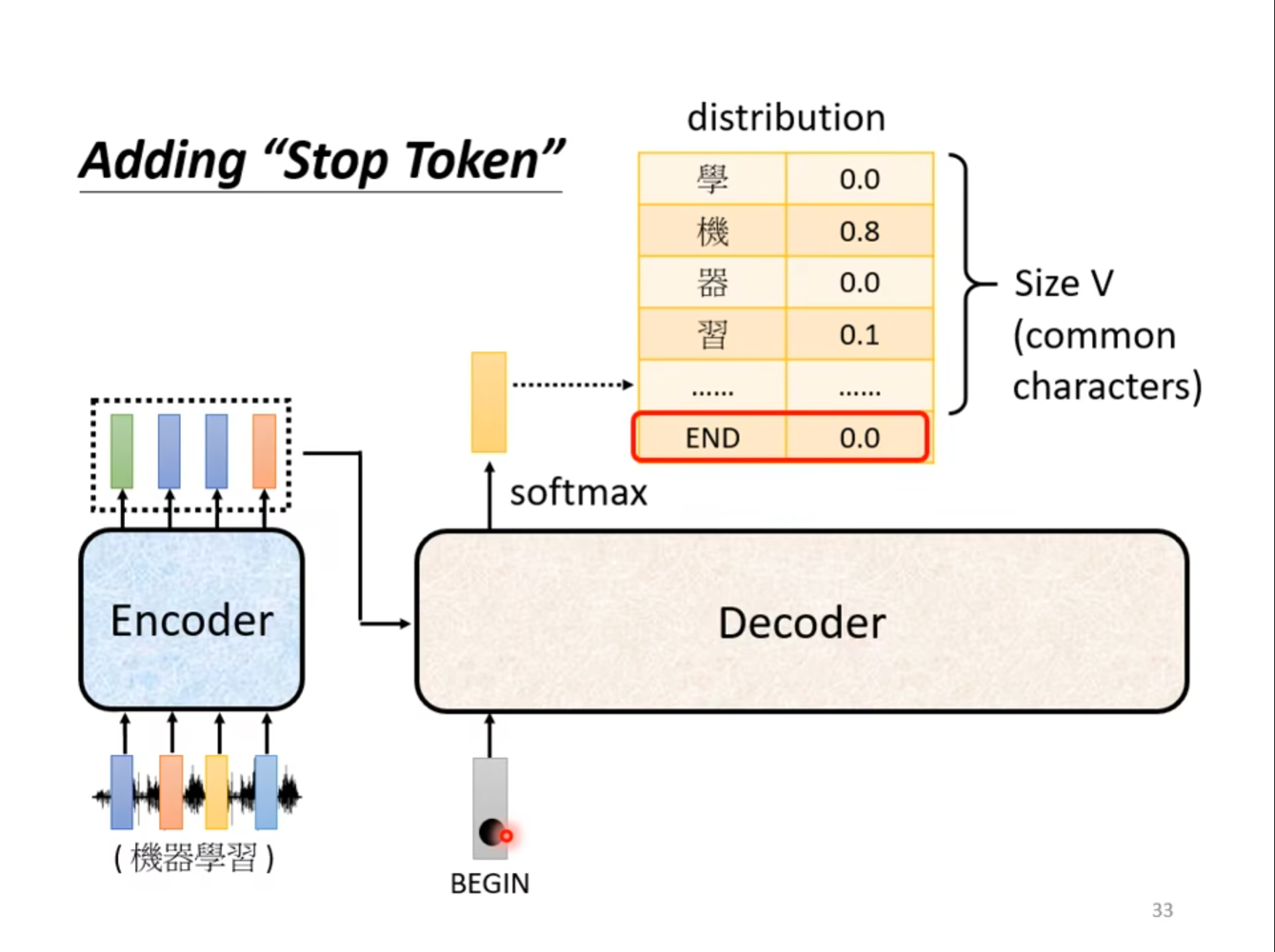 刚才的$ Decoder $只有开始没有结束,为了可以让机器自己学习怎么结束,我们可以通过使用加上一个$ END $在表中的方式,其中当输出为$ END $的时候表示结束。
刚才的$ Decoder $只有开始没有结束,为了可以让机器自己学习怎么结束,我们可以通过使用加上一个$ END $在表中的方式,其中当输出为$ END $的时候表示结束。
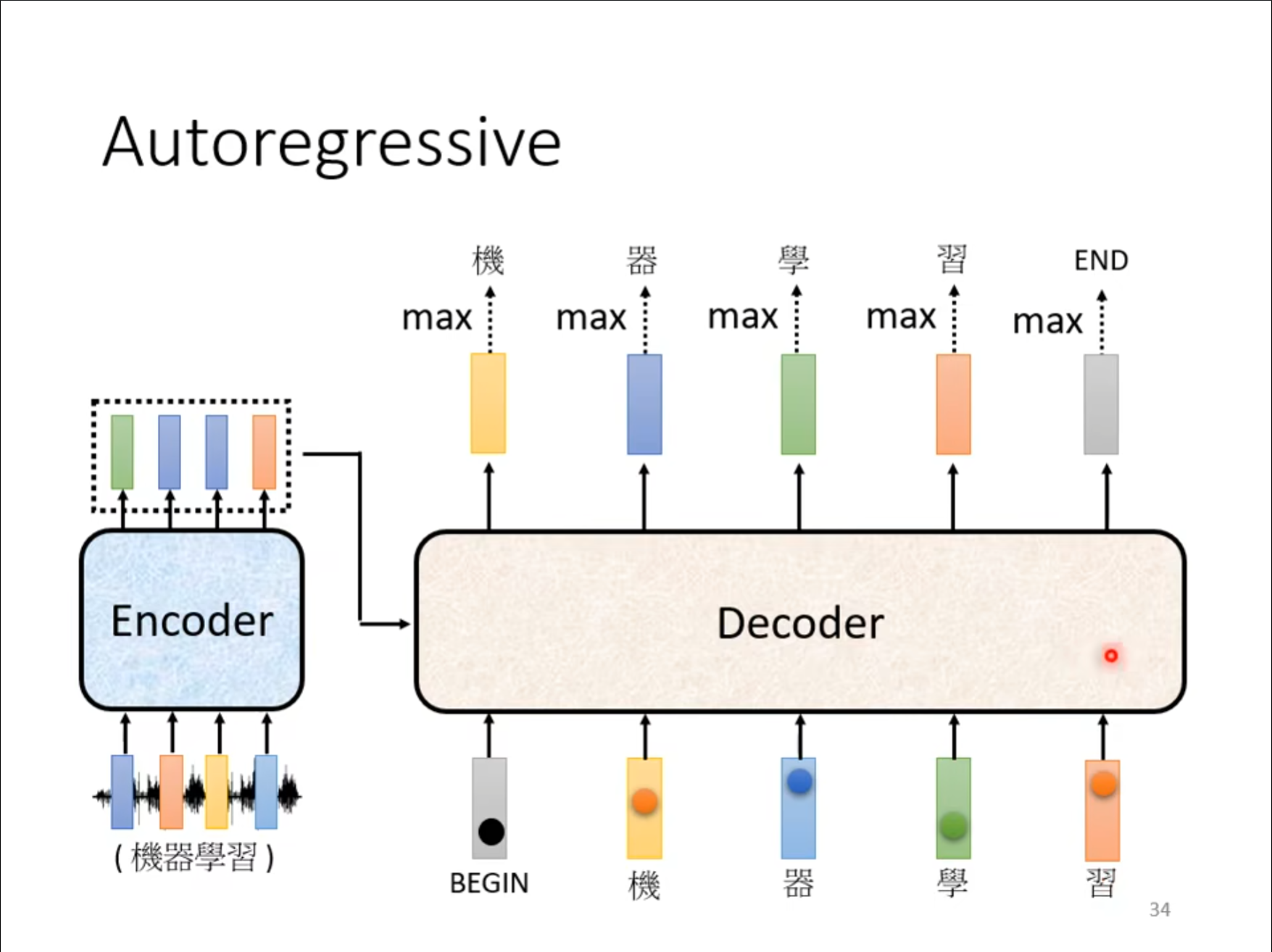
如图中所示,当输入“习”这个词的时候会输出一个$ END $表示结束。
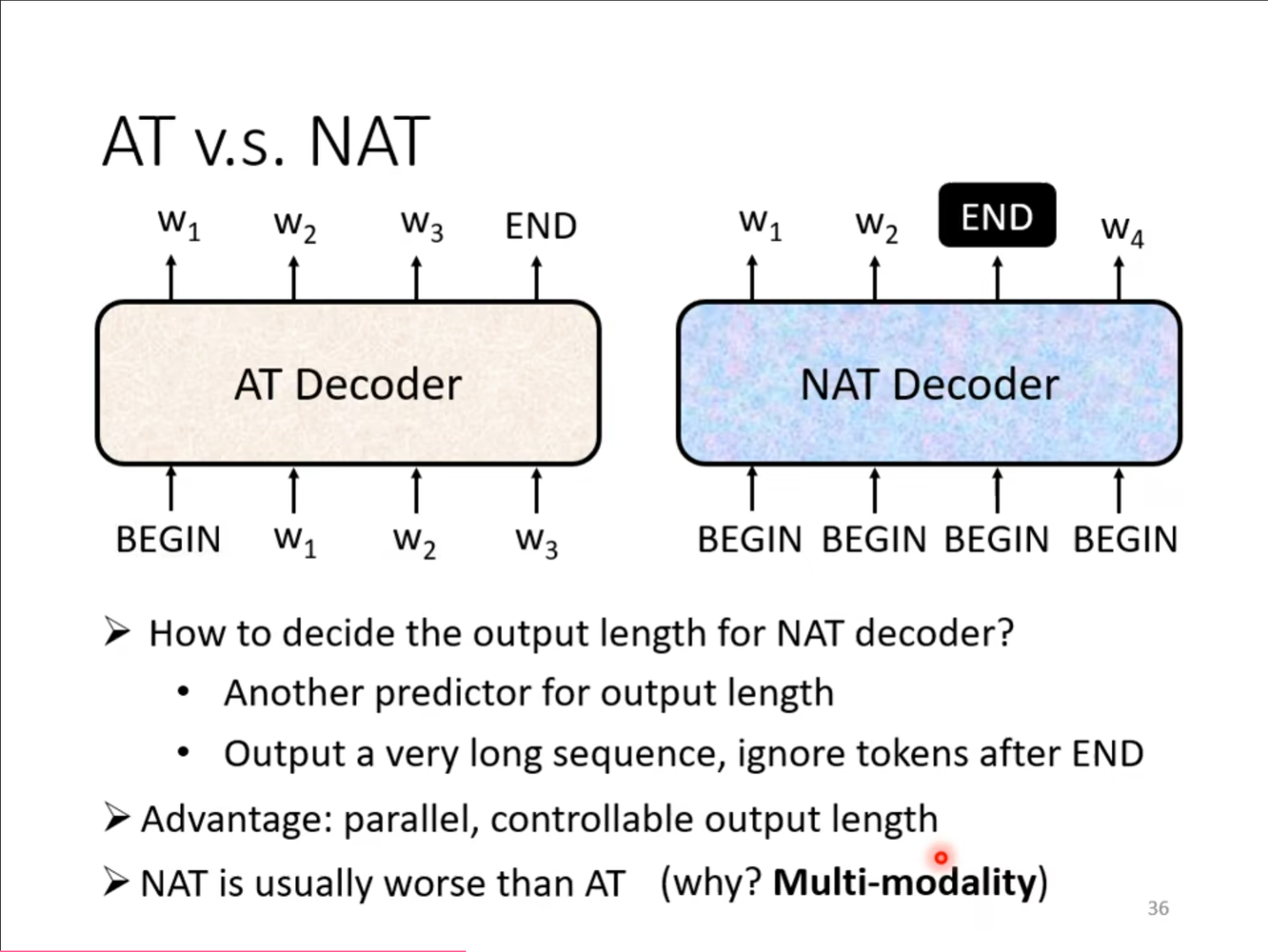
现在对刚才讲的$ Decoder $做一个总结,刚才讲的$ Decoder $全是$ AT\ Eecoder $的形式,但是还有一种$ NAT $的形式,也就是不再一个一个输入,而是采用一次性同时输入的形式,但是这样需要采用一定的措施,例如使用一个新的预测将会有几个输出,或者直接输入很多的$ BEGIN $,然后根据$ END $截断,只要$ END $前面的。
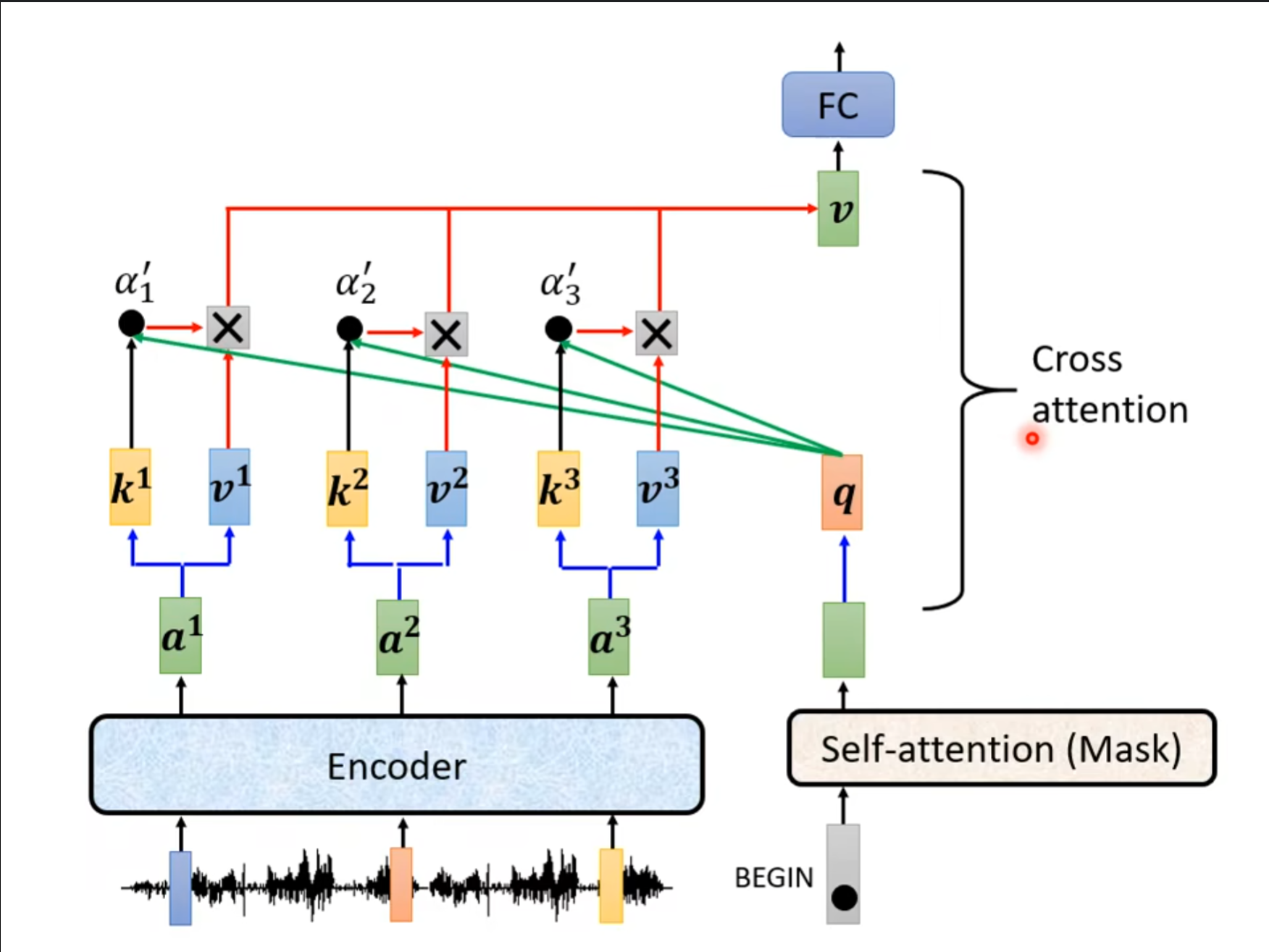
现在需要介绍$ Decoder $是怎么使用$ Encoder $的信息的,通过经过$ Masked \ Multi-Head \ Attention $生成的向量得到一个$ q $,然后使用这个$ q $和$ Encoder $计算得到一个$ v $作为接下来全连接层的输入。
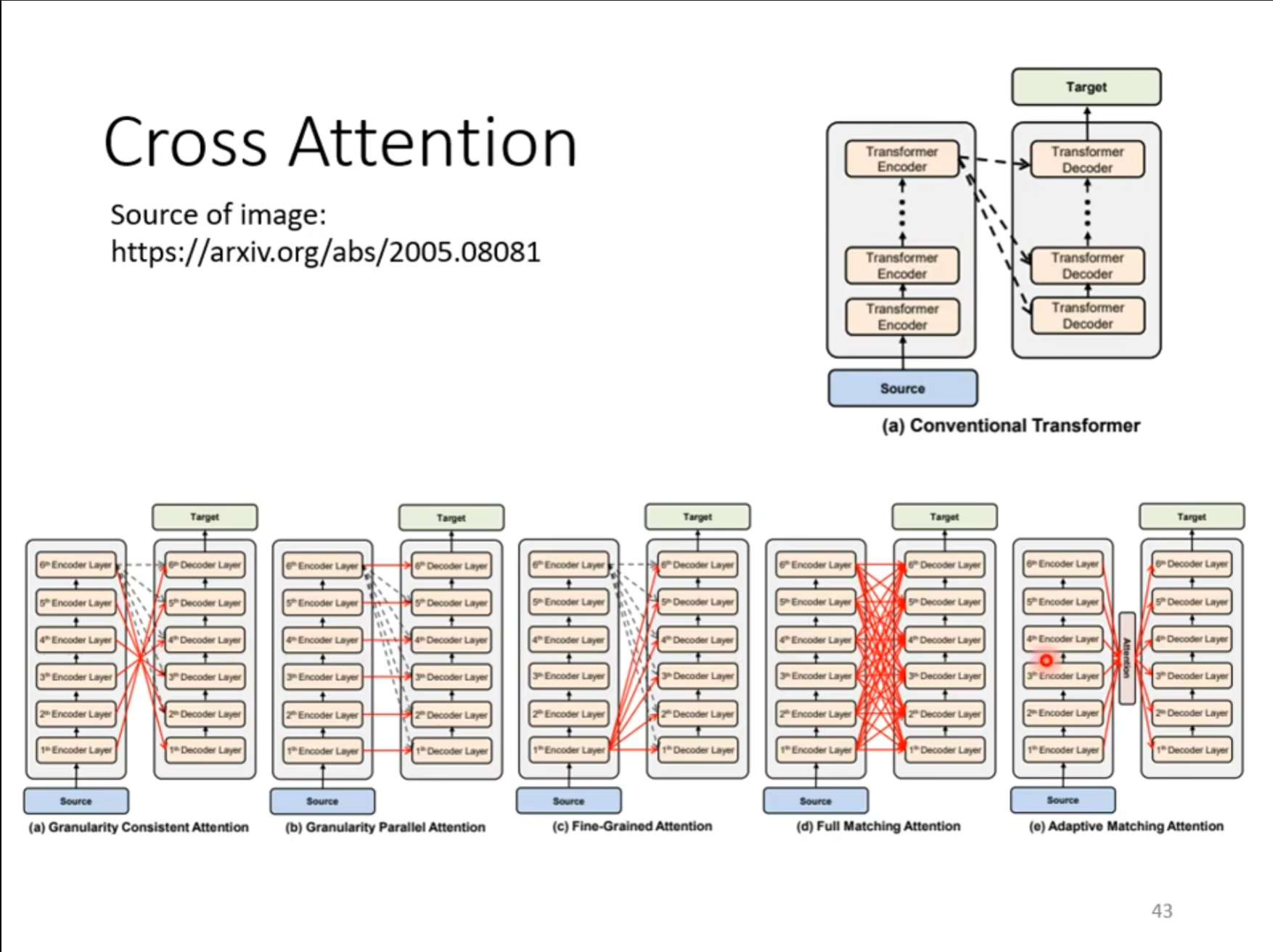
而且未必一定要用$ Encoder $的最后一层的输出作为输入,还可以使用别的方式进行信息的传递。
Training
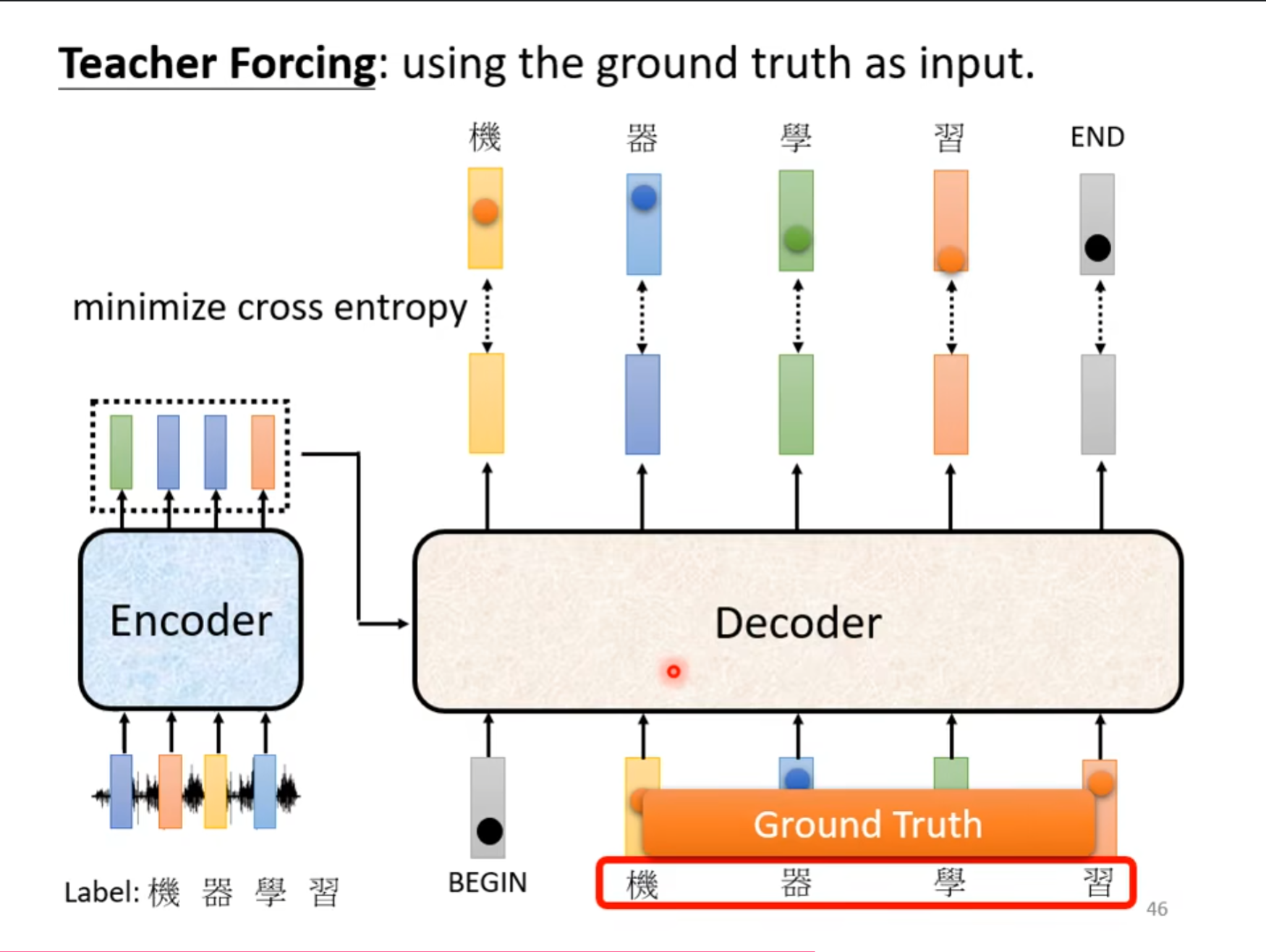
刚才介绍的都是我们已经训练好了一个模型,然后测试这个模型。但是现在要介绍的是怎么训练一个模型,首先我们需要人为的加上标签,也就是使用$ one-hot $表示,同时最小化输出和标签之间的$ cross \ entropy $,同时需要注意的是刚才提的到那个问题,如果在$ Decoder $中预测数据不正确怎么办,因此我们需要使用$ Ground\ Truth $,也就是正确的数据作为输入。
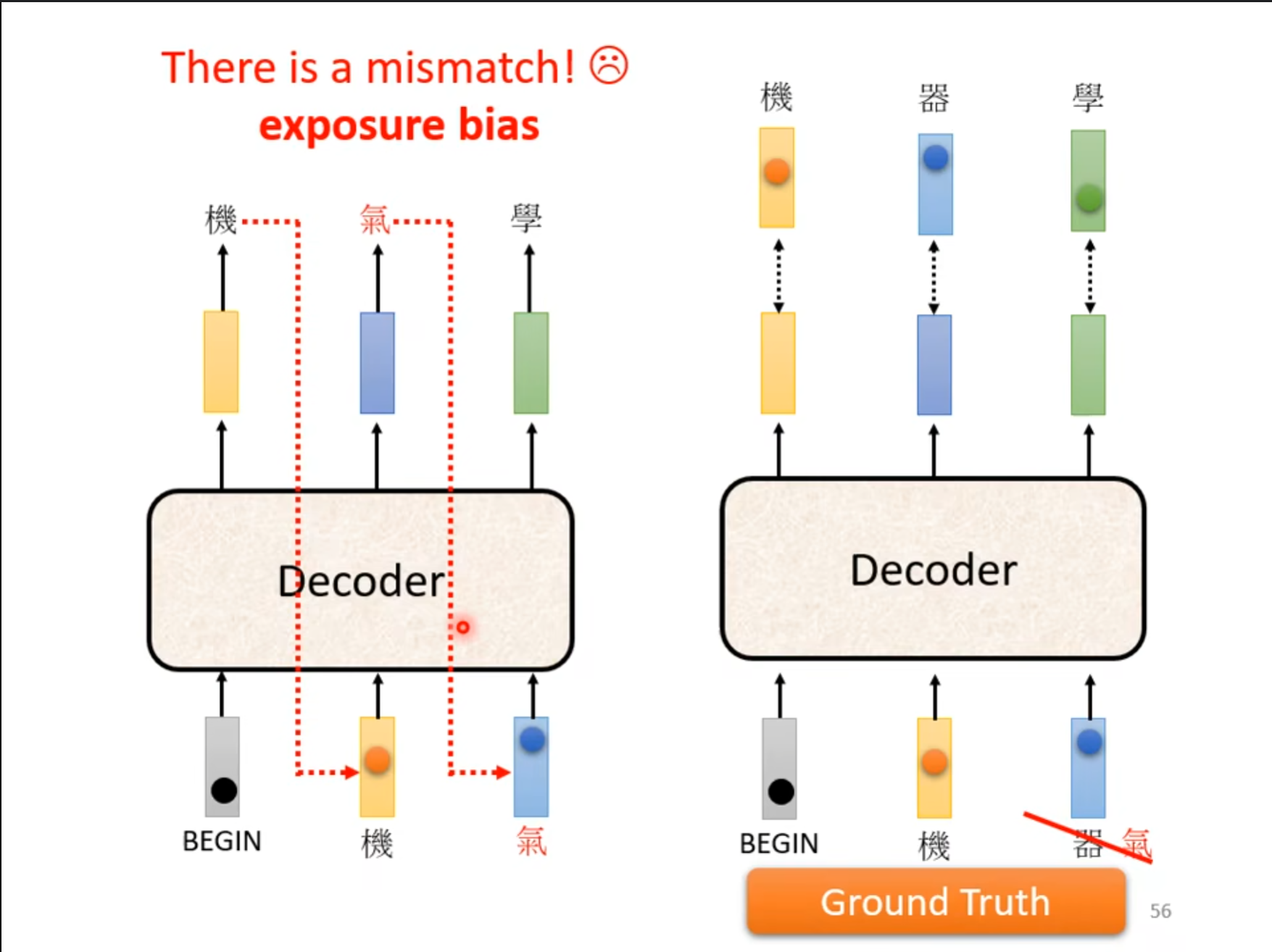
刚才的方法还存在一个曝光偏差($ exposure \ bias $),训练($ training $) 时接受的标签是真实的值($ ground\ truth\ input $),但测试 ($ testing $) 时却接受自己前一个单元的输出($ output $)作为本单元的输入($ input $),这两个$ setting $不一致会导致误差累积。
解决这个问题也不麻烦,只要在训练的时候在正确的标签中故意加入一些错误的数据即可。