异常检测
异常检测算法

第一步:
选择要检测的特征和样本数据。
第二步:
计算不同特征对应的均值和方差。
第三步:
计算每个特征的概率并进行连乘。
评估异常检测系统

对于这个例子,我们假设一个标签对其进行判断,在训练集中仍然仅使用未标注的数据,但是在交叉验证集和测试集上加上标签并将数据集中标注为有缺陷的数据放入,虽然训练集中没有加上标签,但是我们假设他们默认都是正常的,即使其中存在有缺陷但是未被发现的也不会影响最终的模型。
因为我们的训练集仍然是无标签的,因此这仍然是无监督学习,同时如果我们事先知道的缺陷数量过少的话,可以省略测试集,将仅有的缺陷数据全部放入交叉验证集中。
异常检测VS监督学习

异常检测:
有大量的正常数据,但是仅有少部分的异常数据
更倾向于应对无法预知的情况,例如飞机制造,我们无法确定未来会有什么问题,可以是发动机问题,可能是雷达问题,对于这种无法确定异常特征的情况,更适合用于异常检测,因为我们是使用正常的数据作为训练集,同时根据异常数据和正常数据的不同来确定。
监督学习:
用大量的正常数据和异常数据,可以知道经常是那些地方会出问题,例如垃圾邮件判断,我们需要的特征是基本不会改变的,与此相反,对于诈骗来讲,欺诈的方式不断的变化,我们无法固定因此更倾向使用异常检测的方式。
特征选择
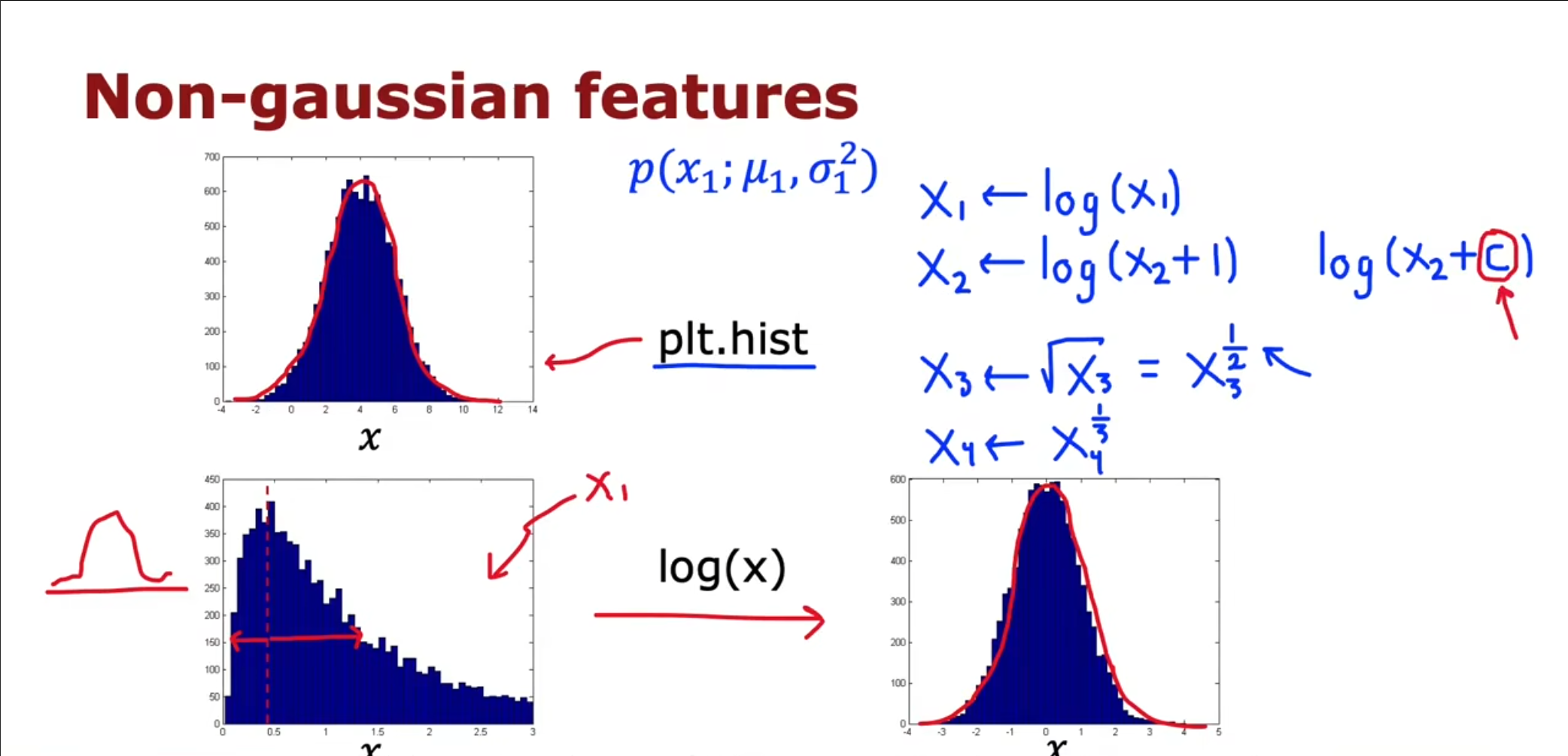
对于选择的特征来讲,可以绘制出它的分布图,然后通过分布图判断其是否符合高斯分布,如果不符合可以对其进行一些调整,例如开方,取对数等等,使其更加符合高斯分布。
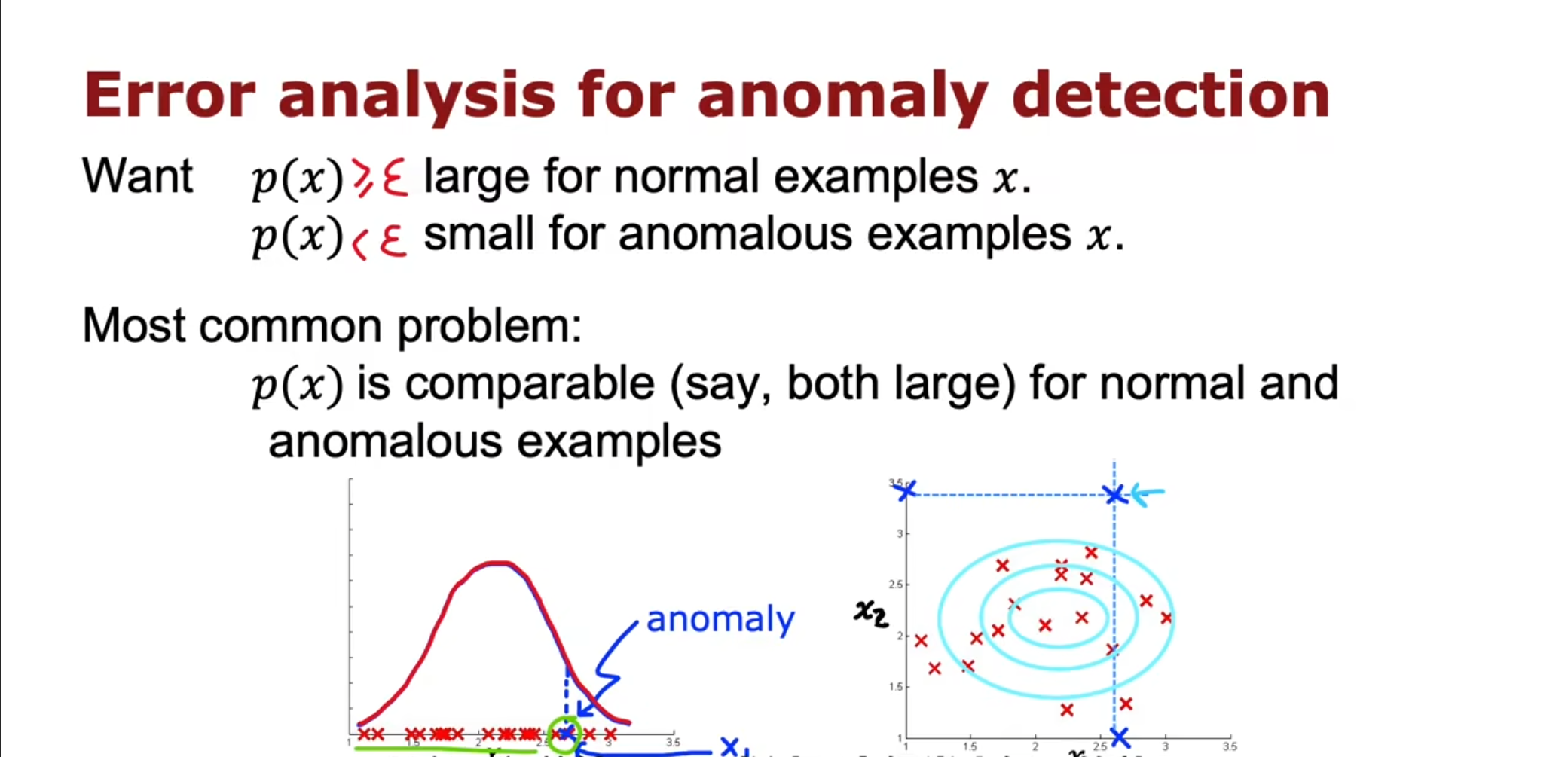
如果存在交叉验证集中的数据属于异常数据,但是它的$ P $却不是很小,那么可以进行错误分析,将其被作为异常数据原因作为新的判断特征。例如一个人在进行交易的时候别的特征都很正常,但是打字的速度却非常快,那么就可以将这个特征作为新的特征。
 ‘
‘
也可以将不同的特征进行组合,使得其在正常的样例中的$ P $很大,但是对于异常样例很小。